Cơ bản về Xử lý ngôn ngữ tự nhiên và ứng dụng cho tiếng Việt
Cơ bản về Xử lý ngôn ngữ tự nhiên và ứng dụng cho tiếng Việt
Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) là một trong những nhánh khó của trí tuệ nhân tạo. Bởi lẽ ngôn ngữ là một hệ thống phức tạp để giao tiếp giữa những động vật bậc cao hay có năng lực tư duy như con người. Nếu NLP được giải quyết thành công đồng nghĩa với việc máy tính có thể hiểu và sử dụng ngôn ngữ tự nhiên để giao tiếp như chúng ta.
1. Sơ lược về ngôn ngữ tự nhiên
Ngôn ngữ tự nhiên không giống với ngôn ngữ nhân tạo như ngôn ngữ máy tính (C, PHP, …). Trên thế giới hiện nay có khoảng 7000 loại ngôn ngữ. Có nhiều cách để phân loại, một số cách phân loại ngôn ngữ phổ biến như dựa vào: nguồn gốc, đặc điểm, …
| PHÂN LOẠI NGÔN NGỮ THEO NGUỒN GỐC | |||||
| Loại | Ấn – Âu | Xê-mít (Semite) |
Thổ | Hán Tạng (Tạng-Miến) |
Nam Phương |
| Ví dụ | Dòng Ấn độ, Hy lạp, German… | Dòng Semite, Do Thái, Ả Rập, Ai cập, Kusit ,.. | Thổ Nhĩ Kỳ | Dòng Hán, Tạng-Miến… | Dòng Nam-Thái, Nam Á (Tiếng Việt) |
| PHÂN LOẠI NGÔN NGỮ THEO ĐẶC ĐIỂM | |||||
| Loại | Hòa kết (Flexional) |
Chắp dính (Agglutinate) |
Đơn lập (Isolate) |
Tổng hợp (Polysynthetic) |
|
| Ví dụ | Đức, Anh, Nga… | Thổ Nhĩ Kỳ, Nhật Bản, Triều Tiên… | Tiếng Việt, Hán… | Chukchi,Aniu… | |
Do đó tiếng Việt được xếp vào loại đơn lập – tức phi hình thái, không biến hình. Cùng với đó, tiếng Việt được viết theo trật tự S – V – O. (subject (S), verb (V) and object (O)).
Một vài so sánh các cách sắp xếp trật tự câu.
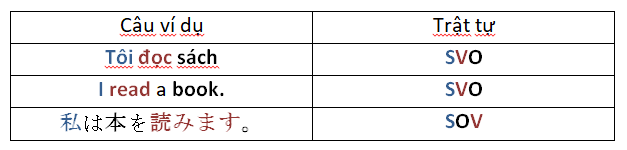
Các cách sắp xếp trật tự câu
2. Xử lý ngôn ngữ tự nhiên
2.1 Ngôn ngữ hình thức – Formal Language
Ngôn ngữ hình thức (Formal Language) là một tập các chuỗi (string) được xây dựng dựa trên một bảng chữ cái (alphabet), được ràng buộc bởi các luật (rule) hoặc văn phạm (grammar) đã được định nghĩa trước. Alphabet có thể là tập các ký tự trong ngôn ngữ tự nhiên (Natural Language) hoặc tập tự định nghĩa các ký tự. Mô hình ngôn ngữ tự nhiên tuân theo quy luật của chuỗi Markov và được hình thức hóa đầu tiên bởi Noam Chomsky được gọi là ‘Mô hình phân cấp Chomsky’. Sau này những mô hình này được dùng để tạo ra ngôn ngữ lập trình hoặc các ứng dụng trong các nghiên cứu dịch tự động.
Tiền đề trong việc xây dựng lý thuyết Automata là ngôn ngữ hình thức
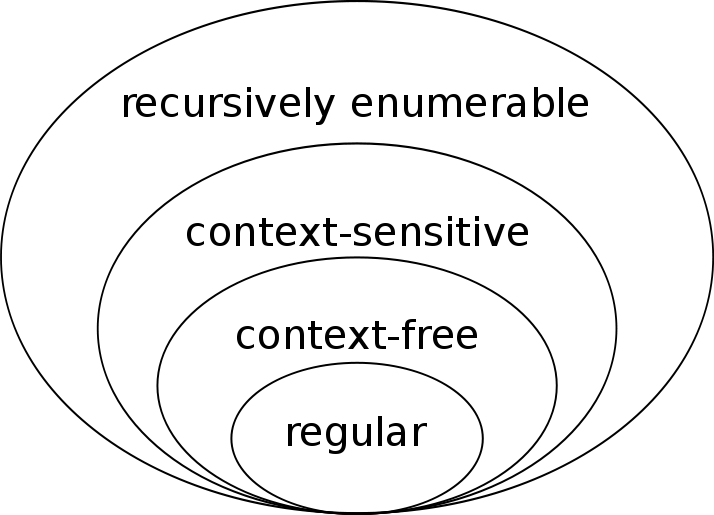
Mô hình phân cấp Chomsky.
2.2 Các khái niệm cơ bản
- Bộ chữ (Alphabet Set): tập các ký hiệu (vô hạn hoặc hữu hạn).
Ví dụ: Tập 26 chữ Roman alphabet, Tập ∑ ={0,1}, …
- Chuỗi (String) hoặc từ (Word): là một chuỗi các chữ cái trên Alphabet nào đó
Ví dụ ‘abc ‘; ‘0101110’ ; …
Chuỗi rỗng (không chứa ký tự nào trong Alphabet). (ký hiệu ԑ , |ԑ| = 0).
- Ngôn ngữ rỗng (Empty Language): một ngôn ngữ không chứa bất kì câu nào được gọi là ngôn ngữ rỗng (ký hiệu: ∅).
- Một ngôn ngữ trên một bộ chữ Σ là tập các chuỗi trên Σ . Σ* là tập chứa tất cả các chuỗi trên Σ bao gồm cả ԑ. Ví dụ với Σ = {0,1} thì: Σ* = { ԑ, 0, 1,00, 01, 10, 11, 000, 001,…}
- Ngôn ngữ L là tập những chuỗi có chiều dài hữu hạn trên một bộ chữ hữu hạn Σ nào đó. Nễu ngôn ngữ L hữu hạn ta chỉ cần liệt kê tất cả các chuỗi để biểu diễn các trường hợp và xét ngữ nghĩa cho từng trường hợp, nhưng vì ngôn ngữ tự nhiên vô hạn nên ta cần văn phạm để xét nghĩa.
2.3 Văn Phạm – Grammar : G = { N, Σ, P, S}
- N: tập các từ vựng phụ trợ, như các phạm trù ngữ pháp, kí hiệu không kết thúc (non-terminal).
- S: tập các từ của ngôn ngữ, gọi là ký hiệu kết thúc (terminal).
- P: tập các luật văn phạm, gọi là luật sản sinh (Production), N
Σ = ∅
- S : là yếu tố nguyên thủy của ngữ pháp, S ∈ N
- Một luật P có dạng : a → b (a, b ∈ N
Σ)
- X là tập các phần tử của chuỗi .
- Xi là tập của những chuỗi có chiều dài i.
- Nếu P trong văn phạm đều có dạng: X → a (X ∈ N, a ∈ N
2.4 Giải thuật phân tích cú pháp Earley
Earley biểu diễn luật P thông qua dấu chấm “•”. Dấu chấm “•” là một siêu ký hiệu (metasymbol) không thuộc về N hay Σ. Vị trí dấu thay đổi theo trạng thái đang xét.
Ví dụ một luật sản sinh P ở trạng thái S(j) : (A → α • β, i).
2.4.1 Giải thuật:
- Khởi tạo
– S(0) được khởi tạo chứa ROOT → • S.
– Nếu cuối cùng ta có luật (ROOT → S•, 0) thì có ta đã phân tích thành công.
- Thuật toán
- Dự đoán: Với mọi trạng thái trong S(j): (X → α • Y β, i), ta thêm trạng thái (Y → • γ, j) vào S(j) nếu có luật sản xuất Y → γ trong P.
- Duyệt: Nếu a là kí hiệu kết thúc tiếp theo. Với mọi trạng thái trong S(j): (X → α • a β, i), ta thêm trạng thái (X → α a • β, i) vào S(j+1).
- Hoàn thiện: Với mọi trạng thái trong S(j): (X → γ • , i), ta tìm trong S(i) trạng thái (Y → α • X β, k), sau đó thêm (Y → α X • β, k) vào S(j).
2.4.2 Ví dụ:
Phân tích câu “tôi ăn quả cam.”
Cho tập luật P:
| S → N VP | 1 |
| S → P VP | 2 |
| VP → V N | 3 |
| VP → V NP | 4 |
| NP → N N | 5 |
| NP → N A | 6 |
| AP → R A | 7 |
Với:
Non-terminal: S, NP, VP, AP.
Terminal: P, N, V, A, R.
| S – câu | AP – cụm tính từ | V – động từ |
| VP – cụm động từ | P – đại từ | A – tính từ |
| NP – cụm danh từ | N – danh từ | R – phụ từ |
Áp dụng giải thuật Earley ta được bảng
| 0 | 1 | 2 | 3 | 4 |
| ‘tôi’ là đại từ P | ‘ăn’ là động từ V | ‘quả cam’ là danh từ N | ||
| 1: S → • N VP | 2 : S → P • VP | 3: VP → V • N | 3: VP → V N • * | 2 : S → P VP • ** |
| 2: S → • P VP | 3: VP → • V N | 4: VP → V • NP | 5: NP → N • N | |
| 4: VP → • V NP | 5: NP → • N N | 6: NP → N • A | ||
| 6: NP → • N A |
Giải thích:
- Bước 0: Ta xét từ gốc ROOT ký hiệu là S, lấy tất cả các luật của S và các non-terminal đầu tiên được suy diễn từ S nếu có. Dấu • được để ngay đầu, có ý nghĩ tiếp theo ta sẽ xét phần tử kế tiếp dấu chấm •.
- Bước 1: Xét từ đầu tiên ‘tôi’ là đại từ nhân xưng, đáp ứng với dòng 2 của bảng 0. Ta dịch chuyển dấu • để xác nhận phần tử đầu thành công và sẽ xét tiếp phần tử kế.
- Bước 2: Xét phần tử kế ‘ăn’ là động từ, cả hai luật 3,4 đều đáp ứng nên ta xét cùng lúc cả hai trường hợp.
- Bước 3: Xét từ cuối ‘quả cam’ là danh từ thỏa luật 3 và kết thúc.
Nếu trong quá trình xét ta gặp non-terminal thì liệt kê tại cùng bảng và duyệt dựa vào đó cho đến khi dấu chấm • ở phía cuối suy diễn và độ dài câu tương ứng với các phần tử đã xét thành công thì kết thúc.
Kết quả được cây suy dẫn:
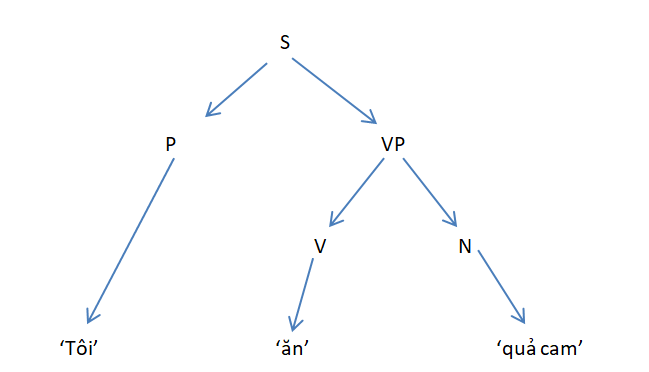
Ví dụ về cây suy dẫn
3. Xử lý tiếng Việt
Đối với xử lý ngôn ngữ khái niệm “Nhập nhằng” là hiện tượng khi câu hoặc từ có nhiều nghĩa dẫn tới việc một câu có thể có nhiều cây suy dẫn. Với tiếng Việt – loại ngôn ngữ đơn lập, nhập nhằng còn xảy ra khi ta có hệ thống từ ghép, từ láy, …
Ví dụ:
- “quần áo” – N N , hoặc “quần áo” – N
- “nóng lòng” – A N , hoặc “nóng lòng” – A
Trong phân tích câu ‘hổ mang bò’, ta được hai cây suy dẫn:
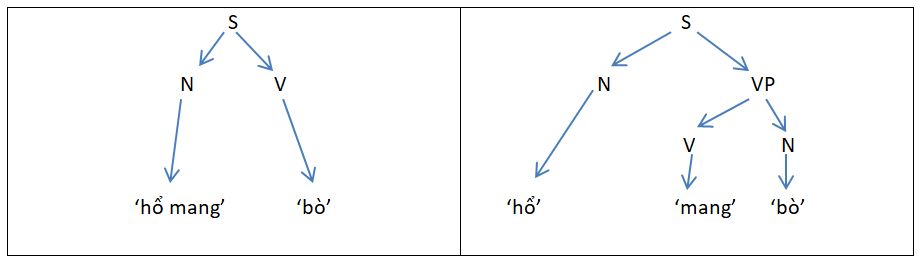
Ví dụ nhập nhằng với kết quả nhiều cây suy dẫn
Tiếng Anh và tiếng Việt có nhiều điểm khác biệt (do loại hình ngôn ngữ, do nền văn hoá,…).
Khác về ngữ âm học, hình vị, ranh giới từ, sự từ vựng hoá (như: ox – bò đực, anh – elder brother ,…); từ loại; trật tự từ, kết cấu câu. Do đó việc áp dụng thuật giải Earley cho tiếng Việt còn gặp nhiều khó khăn.
Cái bài toán giải quyết vấn đề nhập nhằng: Tiền xử lý (Pre-Processing), Phân tích hình thái (Morphology), Phân đoạn từ (Word Segmentation), Phân tích ngữ pháp (Parser), Gán nhãn ngữ nghĩa (Semantics), ….
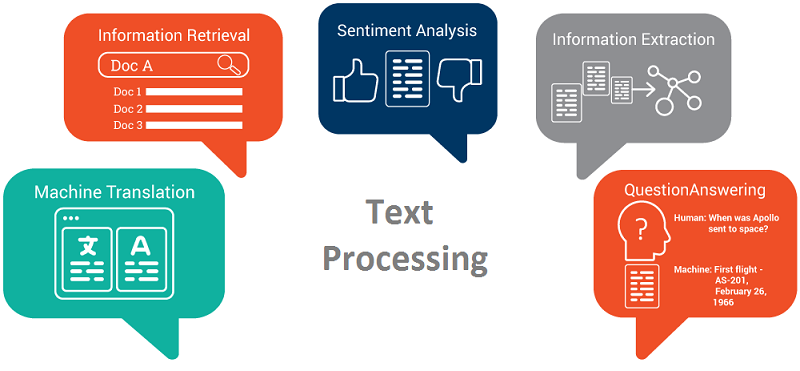
4. Các ứng dụng xử lý ngôn ngữ tự nhiên
Hiện này các ứng dụng tiêu biểu như sửa lỗi chính tả, lỗi cú pháp; dịch tự động; phát hiện vi phạm bản quyền, spam ; tóm tắt rút trích nội dung văn bản, … đều sử dụng công nghệ Natural Language Processing – NLP.
Các ứng dụng xử lý ngôn ngữ tự nhiên
5. Lời kết
Ngôn ngữ là đúc kết trí tuệ của nhân loại. Không chỉ đơn giản là một công cụ để lưu trữ, giao tiếp, truyền đạt tri thức… ngôn ngữ của một dân tộc còn chứa đựng một nền văn hóa, một quá trình lịch sử của dân tộc đó. Gần đây, có xảy ra việc đề xuất cải cách tiếng Việt của PGS.TS Bùi Hiền bị cộng đồng phản đối mạnh mẽ, bởi lẽ phần nào chữ viết cũng là một bộ phận của tiếng Việt và chúng cũng có ý nghĩa mang trong mình nền văn hóa dân tộc. Ngôn ngữ trưởng thành gắn liền với quá trình phát triển của một dân tộc nên đề xuất cải cách đột ngột này nhận được sự phản đổi cũng có thể lý giải được.
Nếu tương lai việc xử lý ngôn ngữ tự nhiên được tối ưu tối đa thì công nghệ trí tuệ nhân tạo – AI sẽ có một bước tiến to lớn trong việc mô phỏng trí tuệ nhân loại. Ở đó, máy móc, robot, … sẽ hiểu và giao tiếp được với con người bằng ngôn ngữ tự nhiên. Và vì hiểu được tư duy của loài động vật bậc cao như chúng ta do đó khả năng hiểu tư duy các loài động vật bậc thấp hơn là đều có thể. Điều này sẽ giúp rút ngắn khoảng cách, rào cản ngôn ngữ của các cộng đồng trên thế giới.
6. Nguồn tham khảo
- Ngữ pháp tiếng Việt [Wiki]
- Natural language processing [Wiki]
- Improvement of Earley parsing for Vietnamese
- Trí tuệ nhân tạo [Wiki]
- Ngôn ngữ [Wiki]

![[Review] chiếc kính Microsoft Hololens 2 đầu tiên đã có mặt tại Việt Nam](https://onetech.vn/wp-content/uploads/cropt/9967_280x250_Hololen-2-First-Look-And-Review-at-Onetech-Asia-1.jpg?v=1.0)




