Một Số Artificial Intelligence Frameworks Và Thư Viện Cần Biết
Cùng với sự phát triển của công nghệ hiện nay, một số lượng dữ liệu khổng lồ được sinh ra và vấn đề giải quyết lượng dữ liệu đó trở nên quan trọng hơn bao giờ hết. Hạn chế về não bộ con người và nhân lực khiến cho các nhà khoa học hướng tới một công nghệ tiên tiến hơn – Trí Tuệ Nhân Tạo (Artificial Intelligence – AI).
Mặc dù việc phát triển nhanh chóng mặt làm cho lượng lý thuyết, thuật toán… của AI ngày càng nhiều, nhưng điều này cũng dẫn đến sự xuất hiện của các frameworks và thư viện giúp các nhà phát triển dễ dàng hơn trong việc tiếp cận công nghệ này.

Machine learning & AI Framework Library
Vì AI là lĩnh vực khá rộng, rất nhiều cá nhân, tổ chức cùng nghiên cứu nên việc lựa cho mình một frameworks và thư viện vừa mạnh mẽ vừa phù hợp cũng không phải là dễ dàng. Cùng Onetech Asia tìm hiểu một số Artificial Intelligence Frameworks và thư viện nổi tiếng nhất dưới đây nhé!
1. Giới thiệu về Trí Tuệ Nhân Tạo – Artificial Intelligence (AI):
1.1. Các khái niệm trong AI:
Artificial Intelligence (AI): Trí tuệ nhân tạo là tất cả các công nghệ có mục đích mô phỏng quá trình suy nghĩ và học tập của con người, bao gồm:
- Machine Learning (ML): Máy học.
- Natural Language Processing (NLP): Xử lý ngôn ngữ tự nhiên.
- Computer Vision: Thị giác máy tính.
- Robotics: Robot học.
- Sensor Analysis: Phân tích cảm biến
- Optimization And Simulation: Tối ưu hóa và mô phỏng.
- Language Synthesis: Tổng hợp ngôn ngữ.

Trí tuệ nhân tạo là tất cả các công nghệ có mục đích mô phỏng quá trình suy nghĩ và học tập của con người
Trong đó quan trọng nhất là:
- Data mining (DM): Khai phá dữ liệu nhằm mục đích lấy được các thông tin hữu ích từ các tập dữ liệu (dataset). Data mining hướng đến xử lý khối dữ liệu lớn nhưng vẫn hiệu quả khi áp dụng cho các tập dữ liệu nhỏ hơn.
- Machine Learning (ML): Máy học là một nhánh của AI, là việc làm cho máy tính có khả năng tự học hỏi được kinh nghiệm trước đó và tự cải thiện hành vi trong một công việc nhất định. Ví dụ các công nghệ thuộc lĩnh vực này : Support Vector Machines (SVM), Decision Trees, Bayes Learning, K-Means Clustering, Association Rule Learning, Regression, Neural Networks, …
- Neural Networks (NNs): Mạng nơ ron nhân tạo là một nhánh của ML, với ý tưởng từ mạng nơ ron của hệ thần kinh xây dựng lên một tập hợp các nút liên kết với nhau được xem như tế bào thần kinh, qua NN này máy tính sẽ có khả năng học.
- Deep Learning (DL): Học sâu là một phần mở rộng của NN, kết hợp nhiều NN tạo thành các kiến trúc multi-layer NN, ở đó một NN là một layer, làm cho việc học máy sẽ hiệu quả hơn nhiều lần. Các kiến trúc DL phổ biến như: Deep Neural Networks (DNNs), Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GAN), …

Giới thiệu về Trí Tuệ Nhân Tạo – Artificial Intelligence
1.2. Bài toán cải thiện tốc độ xử lý trong Machine learning:
1.2.1. Machine Learning process:
- The business understanding – Nắm rõ lĩnh vực kinh doanh: đây là công đoạn để mình hiểu được cơ bản về nội dung, mục đích việc học
- The data understanding – Tìm hiểu dữ liệu: Việc này có mục đích chuẩn bị tài liệu, các thông tin cần thiết để thu thập dữ liệu và lên mô hình huấn luyện.
- The data preparation – Thu thập dữ liệu: Đây là công đoạn quan trọng, vì bộ dữ liệu có được trong công đoạn này sẽ ảnh hưởng đến việc huấn luyện, không được lấy quá chính xác và ngược lại, và thông tin phải là ít sai lệch nhất.
- The modelling – Xây dựng mô hình: Bước này gồm lựa chọn các thuật toán, xây dựng tập model cho tập dữ liệu, tiến hành huấn luyện và chọn ra mô hình hiệu quả nhất.
- The evaluation – Đánh giá: Bước này đánh giá mô hình có đủ tiêu chí để áp dụng thực tiễn.
- The deployment – Triển khai: Sau khi đáp ứng đủ tiêu chí, mô hình sẽ được triển khai cho các dữ liệu thật.
1.2.2. Các phương pháp:
Trong quá trình học máy chung, phần lớn hai công đoạn data preparation và modelling là tốn khá nhiều thời gian (chuẩn bị và thực thi). Để rút ngắn thời gian xử lý, việc cải thiện các thuật toán, hay nâng cấp phần cứng cũng là một phương pháp nhưng không mang lại hiểu quả cao khi xử lý với lượng dữ liệu lớn.
Khi tập dữ liệu của AI đa số là dữ liệu độc lập nên việc chia nhỏ và xử lý song song là có khả năng. Lợi dụng đặc điểm này, có hai phương pháp được sinh ra làm tăng tốc độ xử lý ML/DL với Big Data hiệu quả.
- Sử dụng Graphics Processing Unit – GPU:
Sự khác biệt giữa tính toán trên GPU và tính toán thông thường trên CPU. Đó chính là khả năng tính toán song song nhiều phép tính một lúc. Thông thường, việc tính toán trên CPU (bộ xử lý trung tâm) diễn ra theo cách tuần tự. Tính toán trong GPU lại khác hoàn toàn khi các phép tính được thực hiện song song với nhau. Vì vậy, việc thêm nhiều nhân giúp GPU có sức mạnh tính toán to lớn để thực hiện và kết hợp ma trận thống kê trong mô hình máy học.
Ngoài GPU, ta có thể dùng các thiết bị khác thay thế như Google Tensor Processing Unit 3.0 (TPU), IBM TrueNorth Neuromorphic chip, Microsoft BrainWave (Microsoft), Nervana Neural Network Processor (Kloss), AMD Radeon Instinct (AMD), …
- Sử dụng Map-Reduce:
Map-Reduce được phát minh bởi các kỹ sư Google. Map-Reduce giúp phân chia dữ liệu thành nhiều block và chia cho nhiều máy tính lưu trữ (vẫn đảm bảo tính toàn vẹn và tính sẵn sàng của dữ liệu). Sau đó xử lý các phần nhỏ đó một cách song song và độc lập trên các máy tính phân tán.
Với áp dụng mô hình MapReduce chạy trên lượng lớn các machine (hàng ngàn machine) thì xử lý data lên đến đơn vị Terabytes là bình thường.
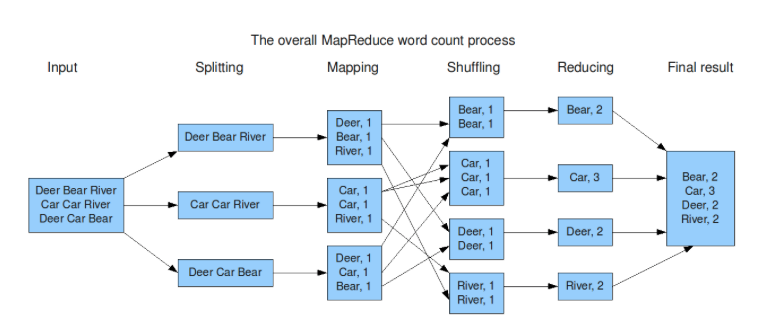
MapReduce process
2. Một số framework và thư viện của Machine Learning:
Với số lượng thuật toán khổng lồ, các frameworks hay thư viện ML được sinh ra cũng được chia ra làm nhiều loại phù hợp các chủ đề, lượng dữ liệu, mục đích, tốc độ … theo từng nghiên cứu.
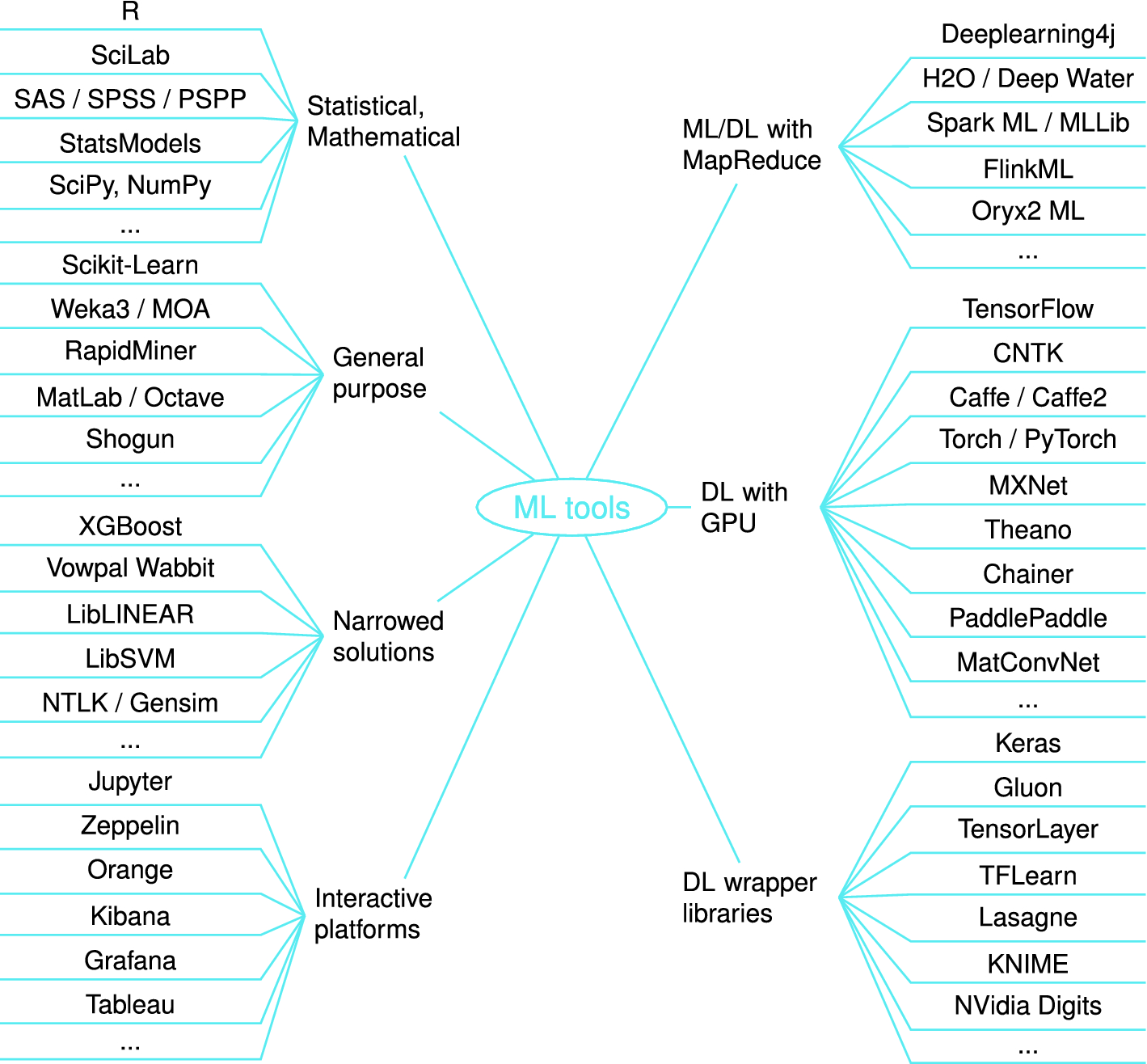
Tổng quan các AI framework và thư viện AI
2.1. Tổng hợp các framework và thư viện Machine Learning:
2.1.1. Các framework và thư viện ML/DL không hỗ trợ cho các phần cứng đặc biệt:
| Tool | Written in | Algorithm coverage | Interface | Workflow | Popularity | Usage | Creator (note) | Licence |
| Shogun (ML library) | C++ | High | Python, Octave, R, Java/Scala, Lua, C#, Ruby | API | Low | Academic | G. Raetsch, S.Sonnenburg
NUMFOCUS |
Open source, GNU GPLv3 |
| RapidMiner (ML/NN/DL framework) | Java | High | Python, R, GUI, API | Yes | High | Academic | R.Klinkenber, I. Mierswa, S. Fischer., et al
RapidMiner |
Business source |
| Weka (ML/DL framework) | Java | High | Java, GUI, API | Yes | High | Academic | Universityof Waikato, New Zealand | Open source, GNU GPLv3 |
| Scikit-Learn (ML/NN library) | Python, C++ | High | Python, API | Yes | High | Academic | D.Cournapeau
INRIA, Google and others |
Open source, BSD |
| LibSVM (ML library) | C/C++ | Low (only SVM) | Python, R, MatLab, Perl, Ruby, Weka, Lisp, Haskell, OCaml, LabView, PHP … | No | Low | Academic | C.C. Chang, C.J. Lin
Taiwan National University |
Open source, BSD 3-clause |
| LibLinear (ML library) | C/C++ | Low (only linear) | MatLab, Octave, Java, Python, Ruby … | No | Low | Academic Industrial | R.E.Fan, K.W. Chang, C.J. Hsieh, X.R. Wang, C.J. Lin
Taiwan National University |
Open source, BSD 3-clause |
| Vowpal Wabbit (ML library) | C++,
own MPI library AllReduce |
Low | API | No | Medium | Academic Industrial | J. Langford
Microsoft, previously Yahoo |
Open source, BSD 3-clause |
| XGBoost (ML boosting, ensemble) | C++ | Low | C++, Java, Python, R, Julia | Yes | Medium | Academic Industrial | T. Chen
DLMC group |
Open source, Apache 2.0 |
2.1.1.1. Shogun:
Shogun là thư việc ML open source được phát triển từ năm 1999. Có thể được chuyển đổi và sử dụng bằng nhiều ngôn ngữ lập trình và môi trường khác nhau như Python, Octave, R, Java/Scala, Lua, C# và Ruby.
- Ưu điểm:
- Shogun là một toolbox chứa nhiều thuật toán ML từ cơ bản đến nâng cao, và những thuật toán mới nhất.
- Được xây dựng, phát triển bằng C++.
- Tích hợp được với nhiều thư viện, ngôn ngữ lập trình ML khác.
- Nhược điểm:
- Được phát triển nhằm mục đích học tập và nghiên cứu, nên khó bảo trì hoặc mở rộng.
- Thiếu tài liệu, chỉ phù hợp nghiên cứu.
2.1.1.2. RapidMiner:
RapidMiner là một mã nguồn mở, là một môi trường cho Machine learning và Data mining và được viết bằng ngôn ngữ lập trình Java. RapidMiner cung cấp một môi trường tích hợp để chuẩn bị dữ liệu, học máy, học sâu, khai thác văn bản, phân tích dự đoán và có thể được mở rộng bằng ngôn ngữ R và Python.
- Ưu điểm:
- Tập hợp đầy đủ các thuật toán, mô hình, sơ đồ bằng Weka và Python để phục vụ cho các mục đích cơ bản.
- Hỗ trợ thêm các thuật toán giải quyết dữ liệu lớn.
- Hỗ trợ cross-platform framework.
- Tương đối phổ biến với mọi người.
- Nhược điểm:
- Là sản phẩm độc quyền nên sẽ gặp khó khăn khi phát triển lên.
2.1.1.3. Weka3:
Weka3 là sản phẩn của trường đại học Waikato ở New Zealand, cũng giống như RapidMiner, Weka3 hỗ trợ khá nhiều thuật toán ML, đặc biệt là Data Mining (DM), và có 4 lựa chọn cho DM: command-line interface (CLI), Explorer, Experimenter, và Knowledge Flow.
- Ưu điểm:
- Đầy đủ các thuật toán, model, schemes cho mục đích chung.
- Có hỗ trợ GUI (API-oriented).
- Hỗ trợ các giai đoạn xử lí DM cơ bản, như: rút trích đặc trưng (feature selection), phân cụm (clustering), phân lớp (classification), hồi quy (regression) và trực quan hóa (visualization).
- Là công cụ nổi tiếng phục vụ việc nghiên cứu về ML
- Nhược điểm:
- Hạn chế trong việc xử lý Big Data, text mining và học bán giám sát (semi-supervised learning).
- Yếu khi áp dụng mô hình trình trự (Sequence Modelling).
2.1.1.4. Scikit-Learn:
Scikit-Learn được biết đến như một thư việc mã nguồn mở, hỗ trợ đầy đủ, toàn diện các thuật toán DM/ML, thống kê, phân tích dữ liệu, … Scikit bắt đầu từ dự án Google Summer of Code của David Cournapeau và được phát triển từ năm 2015.
- Ưu điểm:
- Được phát triển cho mục đích chung, mã nguồn mở, có thể dùng cho mục đích thương mại, là công cụ tương đối phổ biến.
- Được tài trợ bởi nhiều tập đoàn lớn: INRIA, Telecom Paristech, Google, …
- Liên tục được cập nhật và hoàn thiện.
- Liên kết chặt chẽ với nhiều Python package.
- Nhược điểm:
- Chỉ hỗ trợ API-oriented.
- Không hỗ trợ GPU.
2.1.1.5. LibSVM:
LibSVM là thư việc đặc biệt dành cho Support Vector Machine (SVM). Được bắt đầu và phát triển vào năm 2000 tại National Taiwan University. LibSVM tuy viết bằng C/C++ và Java nhưng có cung cấp interfaces cho Python, R, MATLAB,…
- Ưu điểm:
- Định dạng dữ liệu của LibSVM dễ dàng khi áp dụng với các framework hay thư viện khác, định dạng này cũng phù hợp với việc xử lý Big Data.
- Mã nguồn mớ, là công cụ nổi tiếng.
- Nhược điểm:
- Xử lý không hiệu quả với tập dữ liệu rất lớn (very large Dataset) bằng LibLinear, Vowpal Wabbit. Độ phức tạp là O(n2) (trường hợp bình thường), O(n2) trường hợp tệ nhất.
- Chỉ giới hạn cho SVM.
2.1.1.6. LibLinear:
LibLinear là thư viện được xây dựng để xử lí khối dữ liệu lớn bằng linear classification, được phát triển từ năm 2007 tại National Taiwan University. LibLinear cũng viết bằng C/C++ và có hỗ trợ interfaces cho MatLab, Octave, Java, Python và Ruby.
- Ưu điểm:
- Được thiết kế để giải quyết vẫn đề large-scale linear classification.
- Mã nguồn mở, phổ biến.
- Nhược điểm:
- Hạn chế với thuật toán linear regression (LR) và linear SVM.
2.1.1.7. Vowpal Wabbit:
Là Dự án mã nguồn mở do Yahoo khởi xướng và được Microsoft tiếp tục phát triển. Vowpal Wabbit là hệ thống nguồn mở hỗ trợ nhiều phương pháp máy học bằng công nghệ out-of-core learning.
- Ưu điểm:
- Mã nguồn mở, hỗ trợ bởi công ty lớn Microsoft
- Dễ dàng mở rộng.
- Hiệu quả, hiệu suất cao, khai thác CPU, áp dụng các công nghệ tiên tiến.
- Nhược điểm:
- Số lượng phương pháp học ML bị hạn chế.
2.1.1.8. XGBoost:
XGBoost là thư việc mã nguồn mở, xử lý với thuật toán cây quyết định (decision tree) và gradient boosting để tăng tốc độ xử lý.
- Ưu điểm:
- Tốc độ cao, hiệu suất cao.
- Sử dụng triệt để CPU core khi training.
- Nhược điểm:
- Sử dụng cho dữ liệu dạng bảng, không phù hợp với xử lý ngôn ngữ tự nhiên (NLP) hoặc thị giác máy tính (CV).
2.1.2. Các framework và thư viện DL:
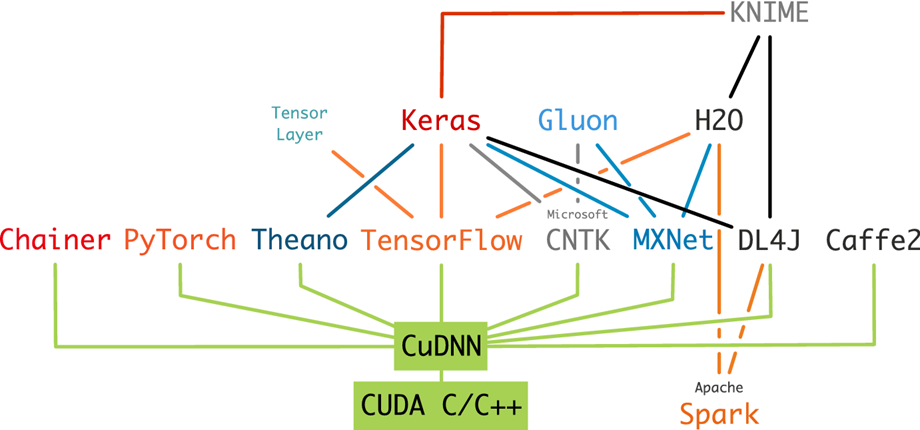
Các framework và thư viện Deep learning
| Tool | Written in | Computation graph | Interface | Popularity | Usage | Creator (note) | Licence |
| TensorFlow (Numerical framework) | C++, Python | Static with small support for dynamic graph | Python, C++ , Java , Go. | Very High, Growing very fast | Academic Industrial | Open source, Apache 2.0 | |
| Keras (Library) | Python | Static | Python, Wrapper for TensorFlow, CNTK, DL4J, MXNet, Theano
|
High, Growing very fast | Academic Industrial | F.Chollet | Open source, MIT |
| CNTK (Framework) | C++ | Static | Python, C++, BrainScript, ONNX | Medium Growing fast | Academic Industrial Limited mobile solution | Microsoft | Open source, Microsoft permissive license |
| Caffe (framework) | C++ | Static | C++, Python, MatLab | High, Growing fast | Academic Industrial | Y.Jia/BAIR | Open source, BSD 2-clause |
| Caffe2 (Framework) | C++ | Static | C++, Python, ONNX | Medium-low, Growing fast | Academic Industrial Mobile solution | Y.Jia/Facebook | Open source, Apache 2.0 |
| Torch (Framework) | C++, Lua | Static | C, C++, LuaJIT, Lua, OpenCL | Medium-low, Growing low | Academic Industrial | R.Collobert, K.Kavukcuoglu, C.Farabet | Open source, BSD |
| PyTorch (Library) | C++, Python | Dynamic | Python, ONNX
|
Medium, Growing very fast | Academic Industrial | A.Paszke,
S.Gross, S.Chintala G. Chanan |
Open source, BSD
|
| MXNet (Framework) | C++ | Dynamic dependency scheduler | C++, Python, Julia, MatLab, Go, R, Scala, Perl, ONNX | Medium, Growing fast | Academic Industrial | Apache | Open source, Apache 2.0 |
| Chainer (Framework) | Python | Dynamic | Python
|
Low, Growing low | Academic Industrial | Preferred Networks | Open source, Owners permissive license |
| Theano (Numerical framework) | Python | Static | Python | Medium-low, Growing low | Academic Industrial | Y.Bengio,
University of Montreal |
Open source, BSD |
2.1.2.1. TensorFlow:
TensorfFlow là thư việc mã nguồn mở được xây dựng và phát triển bởi Google Brain. Thư việc sử dụng data flow graphs để tính toán, hỗ trợ API cho python, C++,… Ngoài ra TensorFlow còn có version TensorFlow Lite là phiên bản nhẹ hơn cho các thiết bị mobile hoặc thiết bị nhúng.
TensorFlow còn được hỗ trợ cho môi trường Google và Amazon cloud.
- Ưu điểm:
- Thư viện đa dạng cho lập trình dataflow, nghiên cứu và phát triển DL
- Có thế tính toán trên CPU/GPU, mobile,..
- Là công cụ phổ biến nhất trong cộng đồng nghiên cứu DL.
- Xử lý hiệu quả cho tính toán mảng đa chiều.
- Nhược điểm:
- API khó sử dụng để tạo DL model.
2.1.2.2. Keras:
Keras là thư việc Python giống như TensorFlow CNTK,.. là công cụ hỗ trợ DL. Có thể thực thi trên CPU và GPU. Được phát triển với các nguyên tắc thân thiện với người dùng.
- Ưu điểm:
- Mã nguồn mở, nhanh.
- Phổ biến, tài liệu tham khảo đầy đủ.
- Nhẹ nhàng và dễ sử dụng.
- Nhược điểm:
- GPU không làm hết hiệu suất 100%
- Kém linh hoạt, không phù hợp cho nghiên cứu kiến trúc mới.
2.1.2.3. Microsoft CNTK:
Microsoft Cognitive Toolkit (CNTK) là bộ công cụ DL xử lý khối data lớn, được phát triển bởi Microsoft Research. CTNK hỗ trợ các kiến trúc FFNN, CNN, RNN và Stochastic Gradient Descent (SGD).
- Ưu điểm:
- Mã nguồn mở, nhanh
- Hỗ trợ format ONNX (Open Neural Network Exchange) làm dễ dàng chuyển đổi model giữa CNTK, Caffe2, PyTorch, MXNet và công cụ DL khác.
- Hiệu suất cao (hơn TensorFlow, Theano) khi sử dụng nhiều máy cho RNN/LSTM.
- Nhược điểm:
- Hạn chế cho các thiết bị mobile.
2.1.2.4. Caffe:
Là DL framework được phát triển bởi Yangqing Jia tại BAIR. DNN được định nghĩa trong Caffe theo layer-by-layer. Dữ liệu được đưa vào qua data layers. Tuy layers mới phải được viết theo C++/Cuda nhưng có một vài layer được hỗ trợ trên Python.
- Ưu điểm:
- Thích hợp xử lý ảnh bằng CNN.
- Mạng được huấn luyện trước (Pre-trained network) có thể được tinh chỉnh (finetuning) trong Caffe Model Zoo.
- Dễ code với Python, Matlab interface.
- Nhược điểm:
- Ít linh động.
- Model được định nghĩa trước phức tạp
- Khó khắn khi định nghĩa mô hình model mới.
2.1.2.5. Caffe2:
Caffe là framework DL nhẹ hơn so với Caffe, được phát triển bởi Yangqing Jia với Facebook. Caffe2 cung cấp các scripts Python để chuyển mode có sẵn từ Caffe sang Caffe2.
- Ưu điểm:
- Cross-platform, hỗ trợ các nền tảng di động
- Linh động, nhẹ hơn Caffe
- Hỗ trợ ONNX
- Nhược điểm:
- Khó khắn cho người mới bắt đầu.
- Không có dynamic graph computation.
2.1.2.6. Torch:
Torch là framework hỗ trợ các tính toán khoa học, thuật toán ML dựa trên ngôn ngữ Lua. Torch được hỗ trợ phát triển bởi Facebook, Google, DeepMind, Twitter, …
- Ưu điểm:
- Linh hoạt, dễ đọc, tái sử dụng code
- Tính môđun, tốc độ nhanh
- Phù hợp cho việc nghiên cứu
- Nhược điểm:
- Không còn được phát triển
- Ít phổ biến
2.1.2.7. PyTorch:
PyTorch là thư viện DL Python dành cho GPU. Được phát triển bởi Facebook. PyTorch được viết bằng python, C và CUDA.
- Ưu điểm:
- Hỗ trợ Dynamic computational graph.
- Hỗ trợ tự động phân biệt cho NumPy và SciPy
- Sử dụng ngôn ngữ Python cho phát triển
- Hỗ trợ ONNX
- Nhược điểm:
- Không hỗ trợ trên mobile
2.1.2.8. MXNet:
Apache MXNet là DL framework hiệu quả và linh hoạt, được phát triển bởi Pedro Domingos tại University of Washington. API hỗ trợ nhiều ngôn ngữ như R, Python, Julia,..
- Ưu điểm:
- Linh hoạt, hỗ trợ nhiều tính năng cho tính toán trên GPU và cả CPU
- Hỗ trợ nhiều ngôn ngữ.
- Hỗ trợ ONNX
- Nhược điểm:
- API khó sử dụng,
2.1.3. Các framework và thư viện ML/DL hỗ trợ MapReduce:
| Tool | Written in | Backends | Interface | Popularity | Algorithm coverage | Usage | Creator (note) | Licence |
| DL4J (DL library for Java) | Java, Scala CUDA cuDNNsupport via JNI | Integration with Spark | Java, Scala, Clojure, Python | Medium | Medium (DL) | Industrial | Skymind | Open source, Apache 2.0 |
| Spark MLlib a , Spark ML a (ML/NN library) | Scala | Integration with Python, R | Java, Scala, Python, R | High for Spark, low for ML | Medium (ML) | Industrial | Apache | Open source, Apache 2.0 |
| H2O (ML/DL framework) | Java | TensorFlow, MXNet, Caffe | REST API, JSON+HTTP, Java, Scala, Python, R | Medium | Medium (ML/DL) | Industrial | H2O
|
Open source, Apache 2.0 |
2.1.3.1. Deeplearning4j:
Deeplearning4j hay DL4J là thư viện DL mã nguồn mở, viết trên môi trường Java để hỗ trợ nghiên cứu xử lý Big Data trên Java.
- Ưu điểm:
- Tiềm năng hỗ trợ Java ecosystem trong DL.
- Cung cấp nhiều pretrained DL model.
- Nhược điểm:
- Java/Scala không phổ biến trong DL/ML như Python
- Không phổ biến bằng H20 và Spark.
2.1.3.2. Apache Spark MLlib và Spark ML:
Mllib và Spark ML là thư viện cung cấp các thuật toán ML hỗ trợ MapReduce.Vì có sử dụng MapReduce nên công cụ xử lý hiệu quả với dữ liệu lớn, và được tích hợp trong Apacha Spark ecosystem. Các thuật toán đa số đã được tối ưu hóa và tiền xử lý cho Hadoop. Điểm yếu của bộ công cụ là chỉ xử lý hiệu quả với data dạng bảng và mất khác nhiều bộ nhớ trong xử lý, và còn khá mới mẻ cho cộng đồng ML/DL
2.1.3.3. H2O, Sparkling Water và Deep Water:
Được phát triển bởi H2O.ai. Đây là framework tương đương với Hadoop dành cho ML/DL trên Big Data. H2O, Sparkling Water và Deep Water có lợi thế trong xử lý dữ liệu lớn phổ biến cho ngành công nghiệp phụ thuộc tăng trưởng dân số như tài chính, bảo hiểm, chăm sóc sức khỏe,… .
2.2. Các framework và thư việc khác:
2.2.1. Các framework và thư viện xử lý dữ liệu khác:
- Một số sản phẩm, thư viện và môi trường ML/DL khác: MatLab, SAS, R, NumPy, SciPy, NLTK, Gensim,…
- Các công cụ có thể tham khảo khác: Jupyter, Zeppelin, Kibana, Grafana, ….
2.2.2. Các thư viện mở rộng hỗ trợ DL:
- Trong TensorFlow: Keras, TensorLayer, TFLearn, Sonnet, PrettyTensor, TF-Slim, tf.keras, tf.contrib.learn, tf.layers,…
- MXNet: Gluon,…
- Theano: Lasagne, Blocks, Pylearn2…
2.2.3. Các thư viện ML hỗ trợ MapReduce khác:
- ApacheFlink: FlinkML,…
- Apache Spark: Oryx2,…
3. Đánh giá các frameworks:
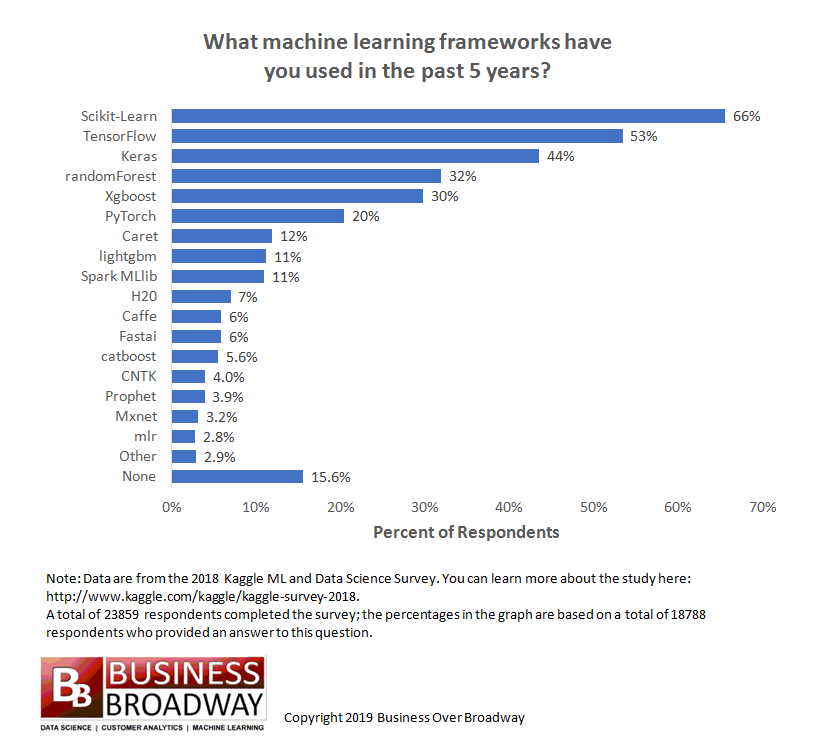
The Kaggle ML and Data Science Survey
- So sánh các DL framework:
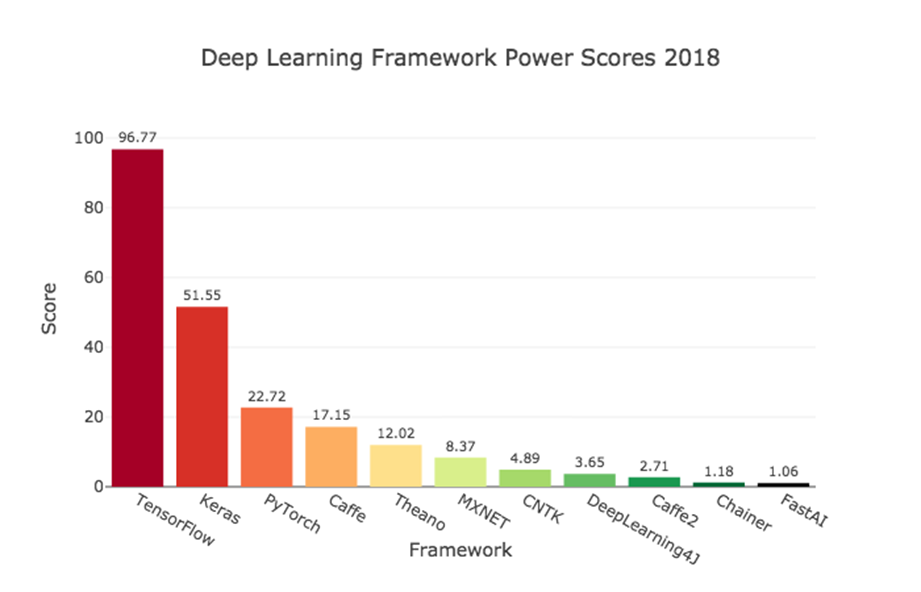
Biểu đồ so sánh các DL framework từ cộng đồng Github
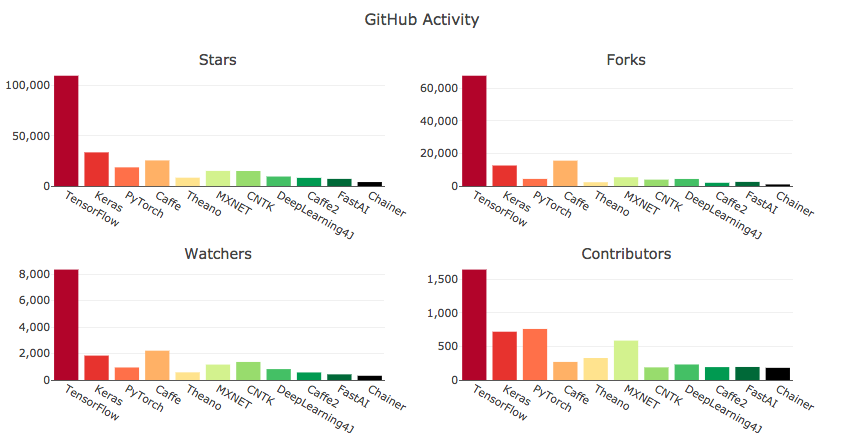
Bảng thống kê độ phổ biến các ML/DL framework
4. Kết luận:
Theo kinh nghiệm từ công đồng ML/DL, Keras là framework thích hợp với những người mới bắt đầu do tính nhẹ nhàng, thân thiện, và đầy đủ model. Sau khi đã quen với môi trường ML/DL thì có thể sử dụng TensorFlow để đi tiến hành các nghiên cứu sâu hơn.
Hầu hết, các thư viện DL tốt cần có các đặc điểm:
- Hỗ trợ tính toán với GPU và các hệ thống phân tán.
- Hỗ trợ các ngôn ngữ lập trình phổ biến: C/C++, Python, Java, R, …
- Chạy được trên nhiều hệ điều hành.
- Thân thiện với người dùng.
- Thời gian từ ý tưởng tới xây dựng và huấn luyện mô hình ngắn.
- Có thể chạy trên trình duyệt và các thiết bị di động.
- Có khả năng giúp người lập trình can thiệp sâu vào mô hình và tạo ra các mô hình phức tạp.
- Chứa nhiều model zoo hay các mô hình DL thông dụng đã được huấn luyện trước (pretrained).
- Hỗ trợ tính toán truyền ngược (backpropagation) tự động.
- Phổ biến, đầy đủ tài liệu, có cộng đồng hỏi đáp lớn.
Đa số các frameowork hiện nay đều có điểm mạnh riêng, do đó, hãy lựa chọn một framework phù hợp tùy thuộc vào mục đích sử dụng và trình độ của mình.
5. Tham khảo:
- https://vi.wikipedia.org/wiki/Khai_ph%C3%A1_d%E1%BB%AF_li%E1%BB%87u
- https://link.springer.com/article/10.1007/s10462-018-09679-z
- https://techtalk.vn/map-reduce.html
- https://kipalog.com/posts/Tong-quan-mo-hinh-lap-trinh-MapReduce






