Giới thiệu AWS GLUE
AWS Glue là một serverless tool được phát triển với mục đích trích xuất (Extract), chuyển đổi (Transform) và tải dữ liệu (Load). Quá trình này được gọi là ETL. AWS Glue cho phép các doanh nghiệp trích xuất dữ liệu từ một nguồn, chuyển đổi dữ liệu và sau đó tải nó vào một data warehouse, tất cả được thực hiện trên đám mây.

AWS Glue cũng là một dịch vụ được quản lý hoàn toàn bởi Amazon, có nghĩa là người dùng không phải quản lý và bảo trì.
Tại sao AWS Glue lại mạnh mẽ đến vậy?
Glue mạnh mẽ bởi nó kết hợp tốc độ và hiệu suất của Apache Spark với tổ chức dữ liệu của Hive. Bạn có thể đã từng nghe về Lambda, một dịch vụ được quản lý hoàn toàn khác của AWS. Không giống Lambda, có thời gian timeout là 15 phút, Glue có thời gian timeout mặc định là 2 ngày. Nếu bạn đã sử dụng Lambda cho một số dự án mà thời gian thực thi quá lâu, bạn có thể chọn Glue, tùy thuộc vào tình huống.
AWS Glue sẽ cho phép bạn tích hợp dữ liệu nhanh hơn bằng cách giảm thời gian phân tích dữ liệu. Nó cũng sẽ tự động hóa các tác vụ tích hợp dữ liệu bằng cách quét các nguồn dữ liệu, xác định định dạng dữ liệu và đề xuất các schema phù hợp để lưu trữ dữ liệu của bạn. AWS Glue chạy mà không cần máy chủ, có nghĩa là không cần quản lý, cung cấp, cấu hình hay mở rộng tài nguyên. Bạn chỉ trả phí cho những tài nguyên được sử dụng khi chạy một công việc.
Cách AWS Glue hoạt động
Chúng ta sẽ tiếp cận theo hướng thực hành Crawler chuyển đổi dữ liệu từ file CSV thông qua AWS Glue để chuyển vào Aurora, chạy nó và xem bảng mà nó tạo ra. Crawler cho phép chúng ta thu thập dữ liệu từ nhiều kho dữ liệu và sau đó tạo một bảng dữ liệu. Kết hợp với AWS Glue, điều này cho phép chúng ta cũng chuyển đổi dữ liệu. Hãy cùng thực hành để xem nó hoạt động như thế nào.
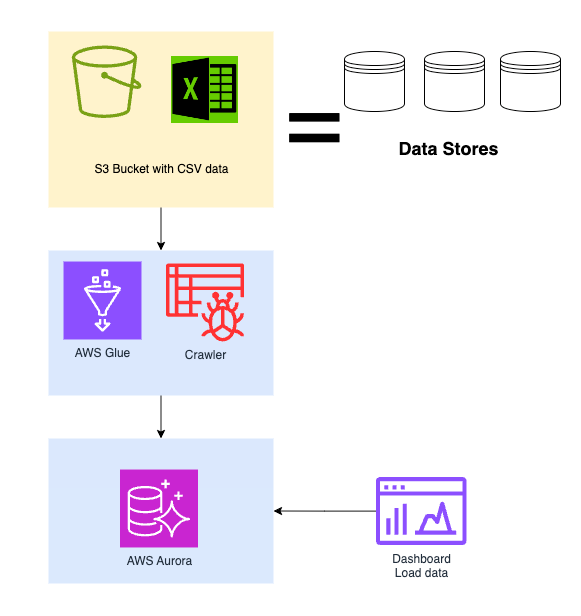
Mô tả luồn xử lý:
- S3 là nơi chứa các bảng dữ liệu dưới dạng file CSV (data của Oracle)
- AWS Glue Crawler vào file CSV đó để tạo bảng dữ liệu tạm thời
- Từ bảng dữ liệu tạm thời sẽ chuyển đổi cập nhật vào Aurora Mysql
Các bước thực hiện với AWS Glue
1. Thiết lập tài khoản AWS
– Bạn cần có một tài khoản AWS để thực hiện hướng dẫn này. Để tạo tài khoản, bấm VÀO ĐÂY.
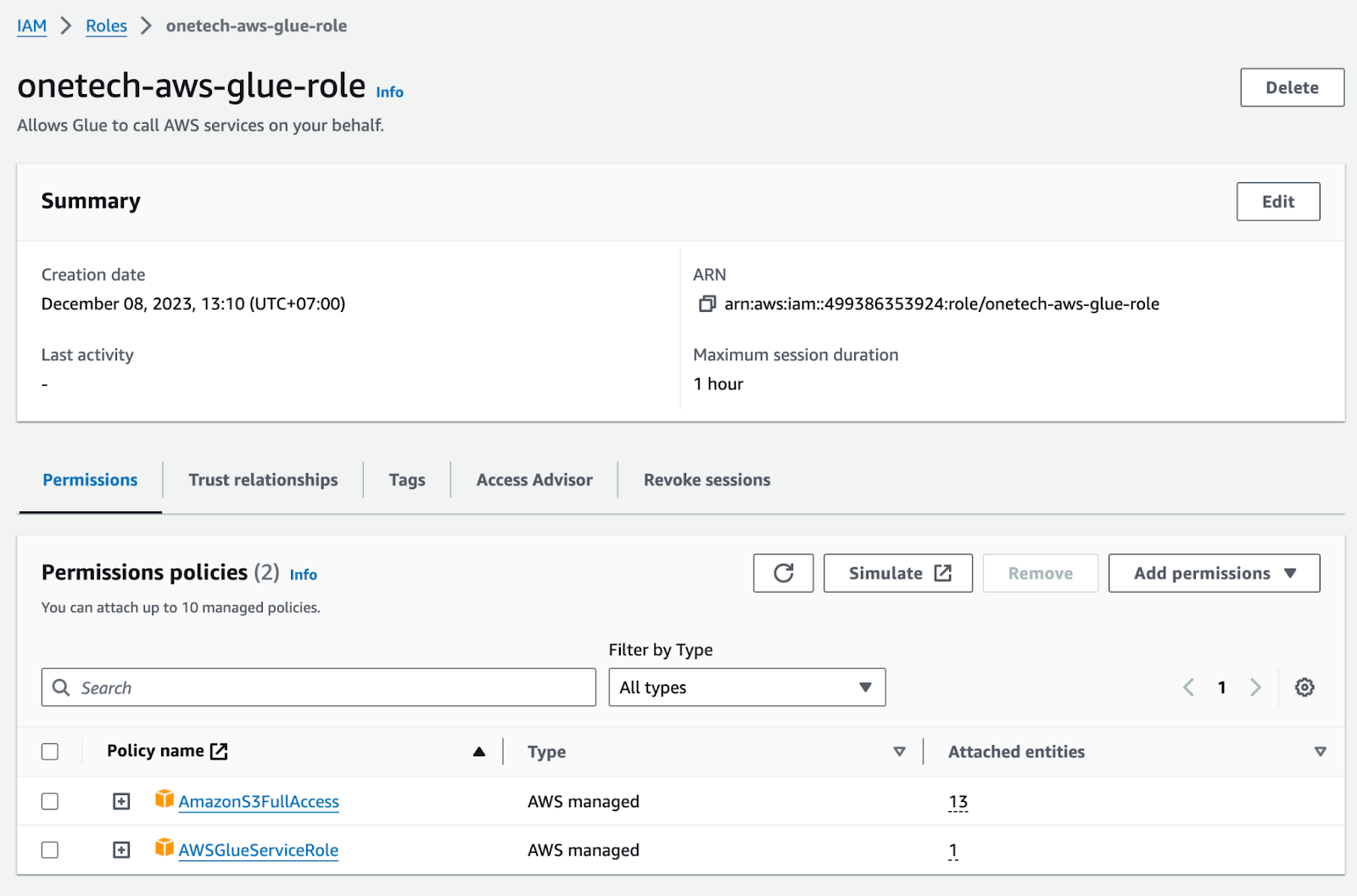
2. Tạo IAM Role cho AWS Glue
– Login AWS console > IAM > Chọn Roles và Tạo Role. Ở đây bạn sẽ chọn dịch vụ Glue từ mục Chọn dịch vụ sẽ sử dụng role này. Sau đó bạn sẽ chọn Policy AWSGlueServiceRole và S3FullAccess > Create role.
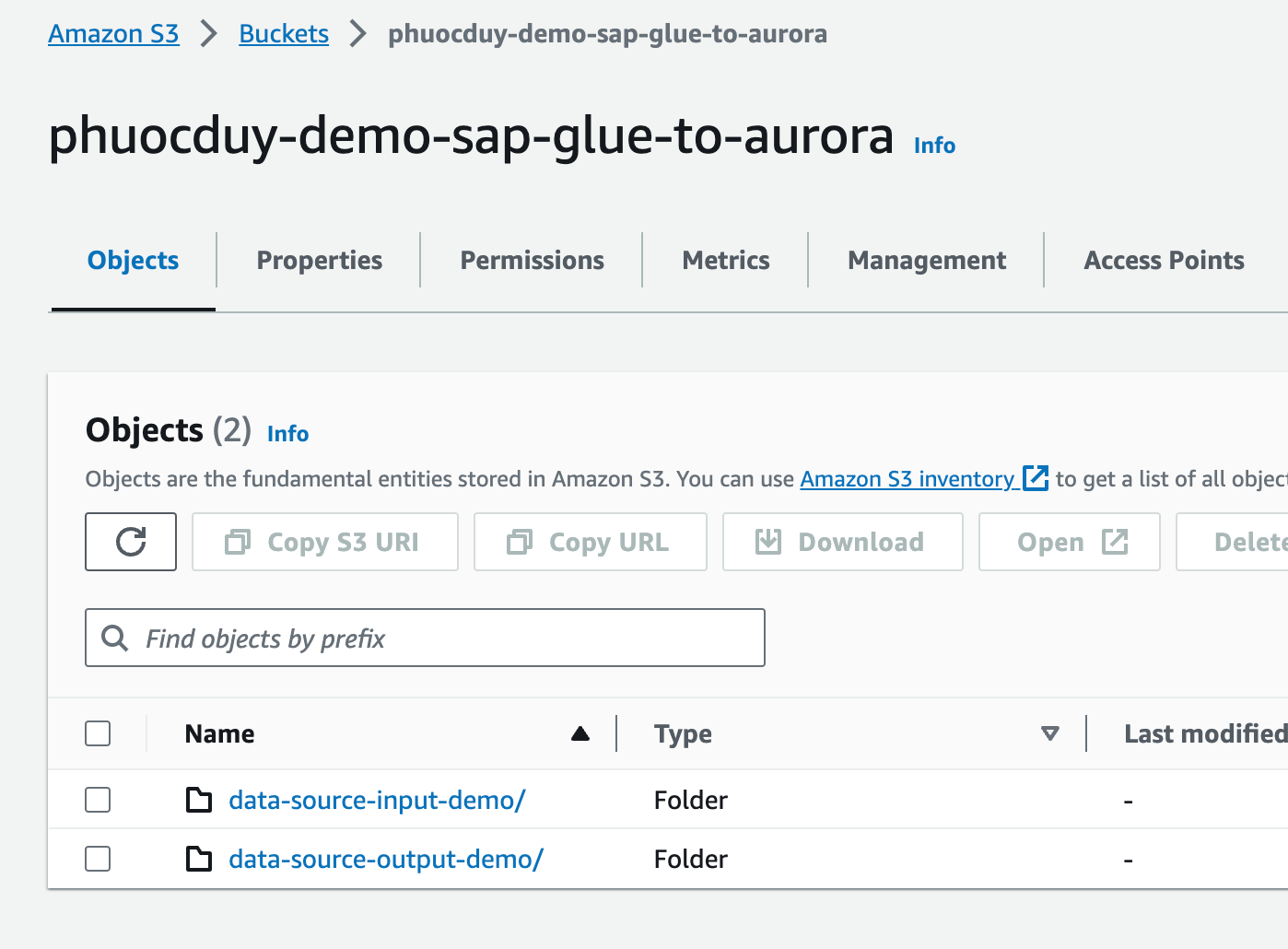
3. Tạo S3 bucket với 2 folder
data-source-input-demo/ > folder chứa CSV input
data-source-output-demo/ > folder chứa CSV output từ Glue
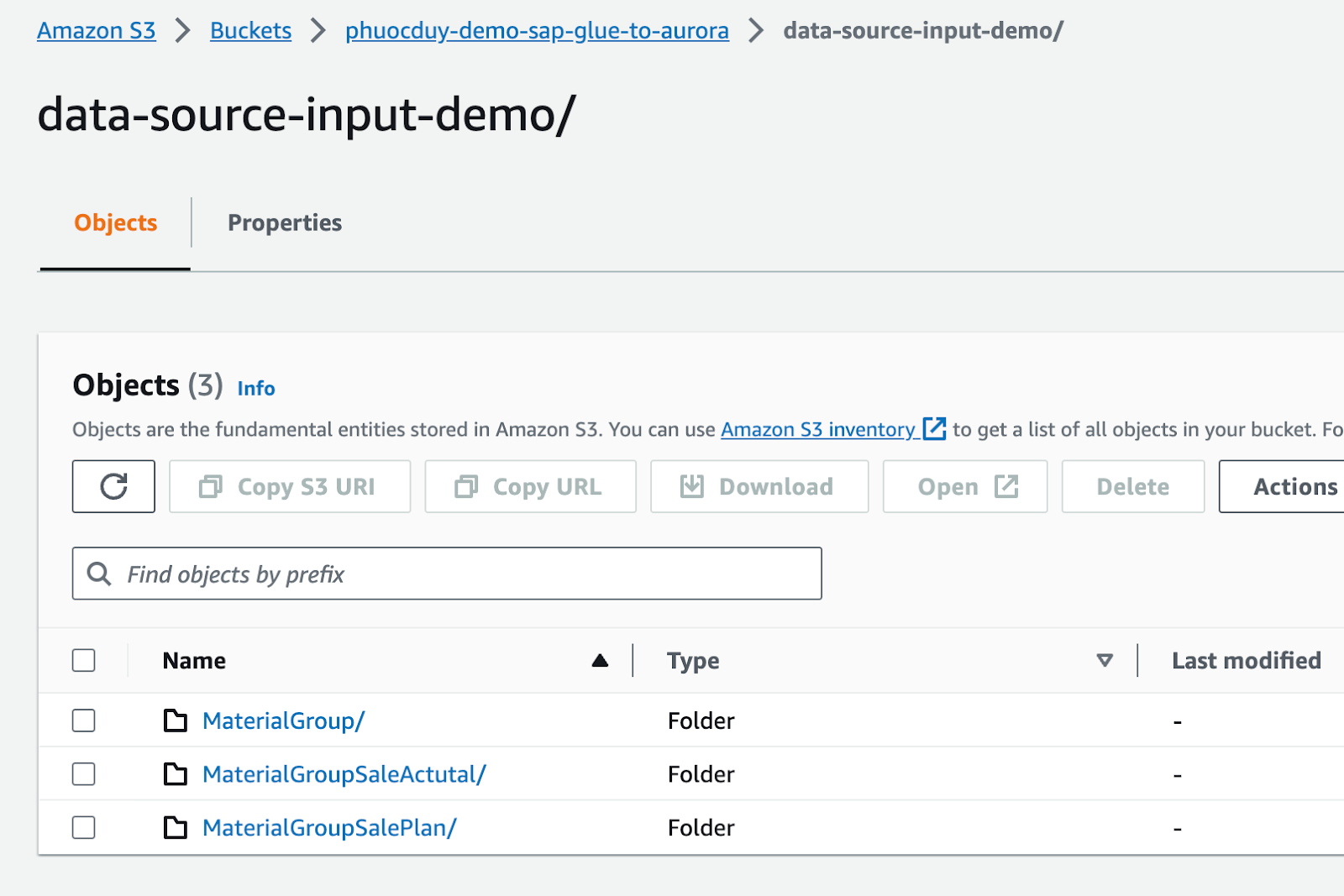
Bên trong data-source-input-demo/
Ta sẽ chuẩn bị table để xử lý Import vào Aurora
MaterialGroup
4. Create Glue Data Catalog
Vào màn hình AWS Console Glue > Databases > Add database:
Data-source-input-demo
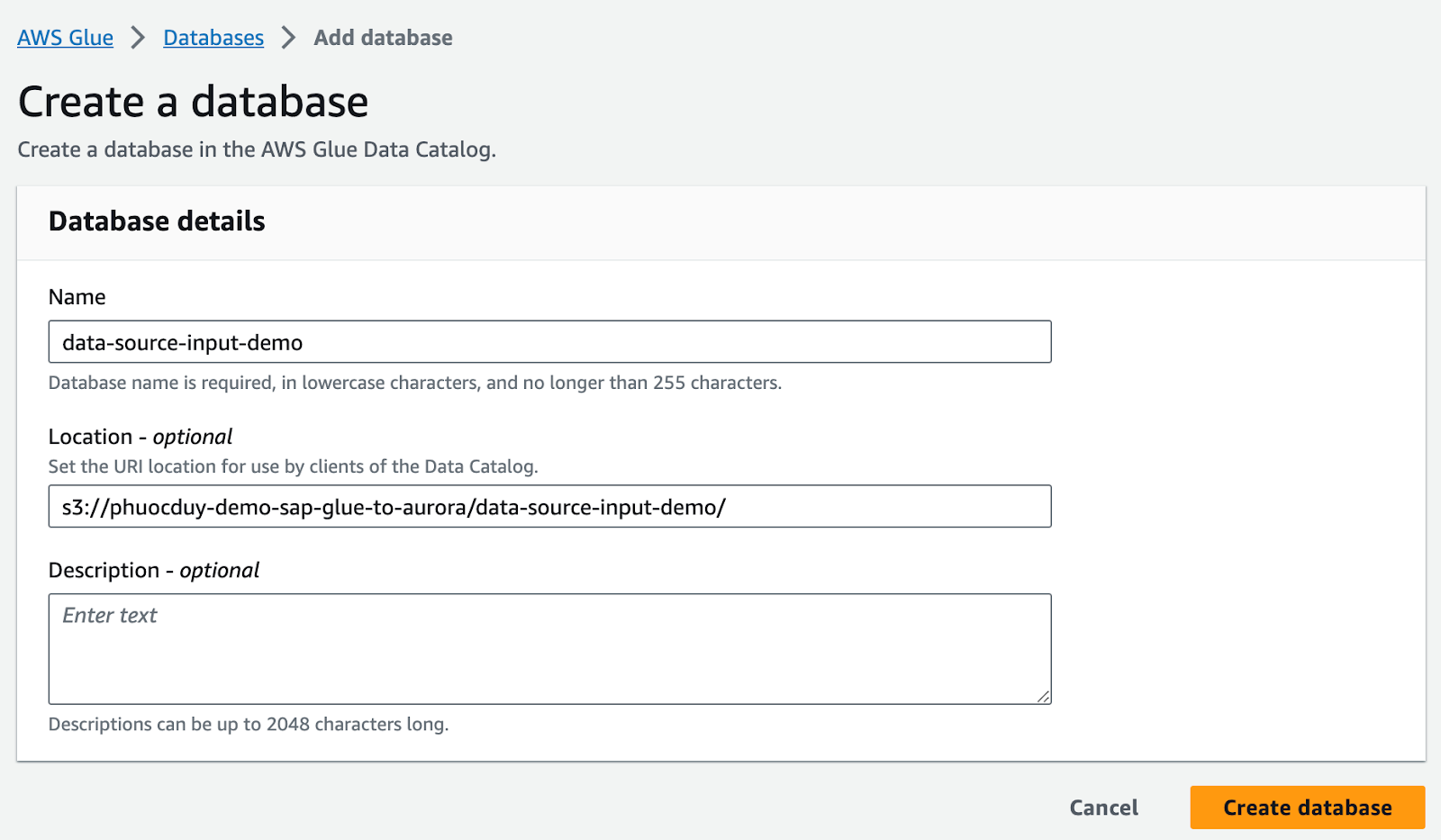
5. Tiến hành tạo table với những file CSV trên S3
VVào màn hình AWS Console Glue > Tables > Add Tables Using Crawler:
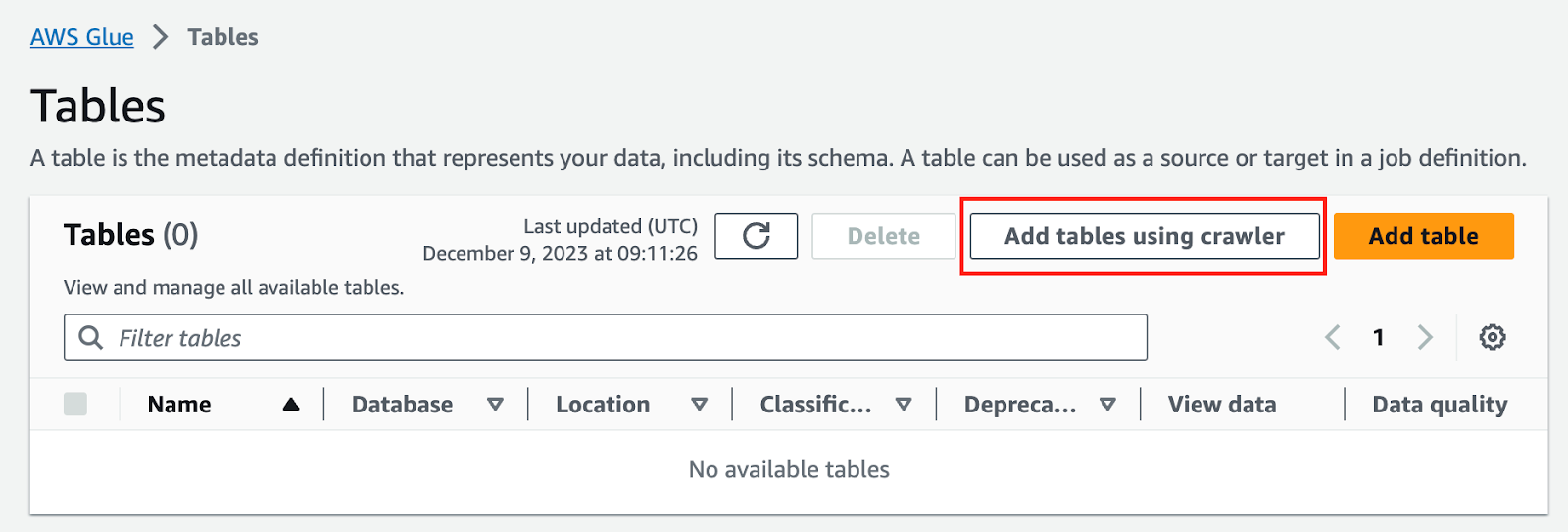
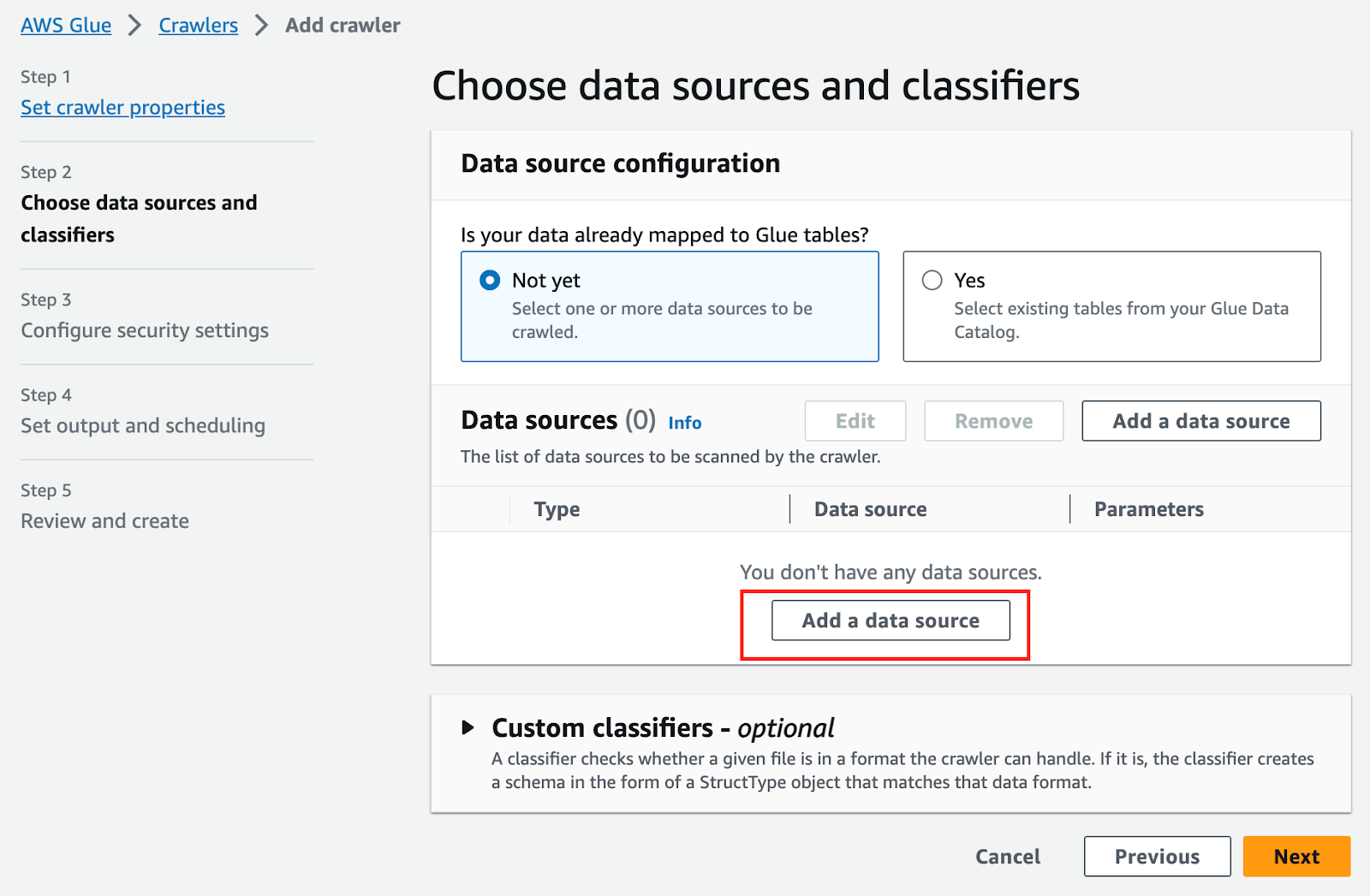
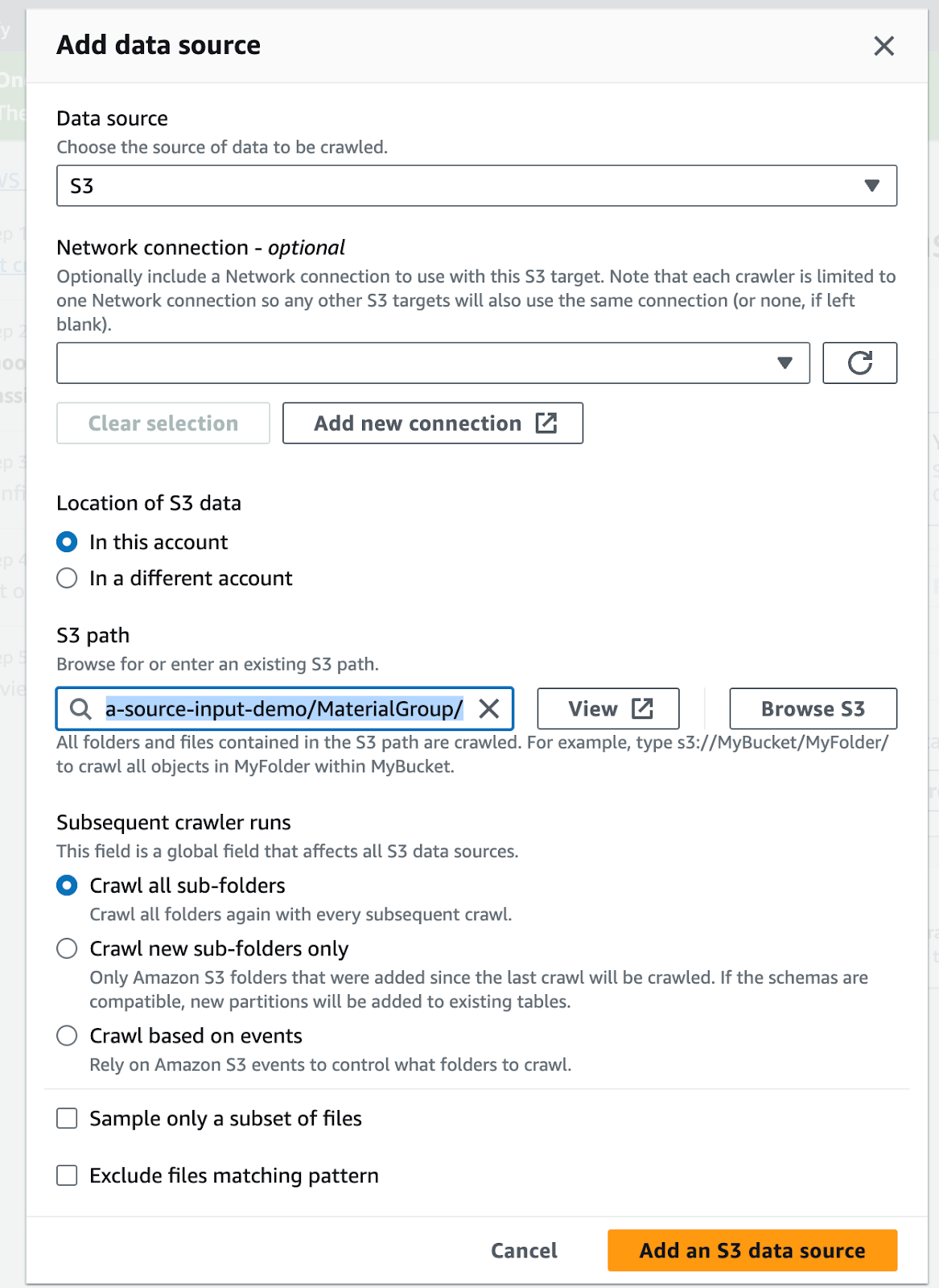
Add an S3 data source
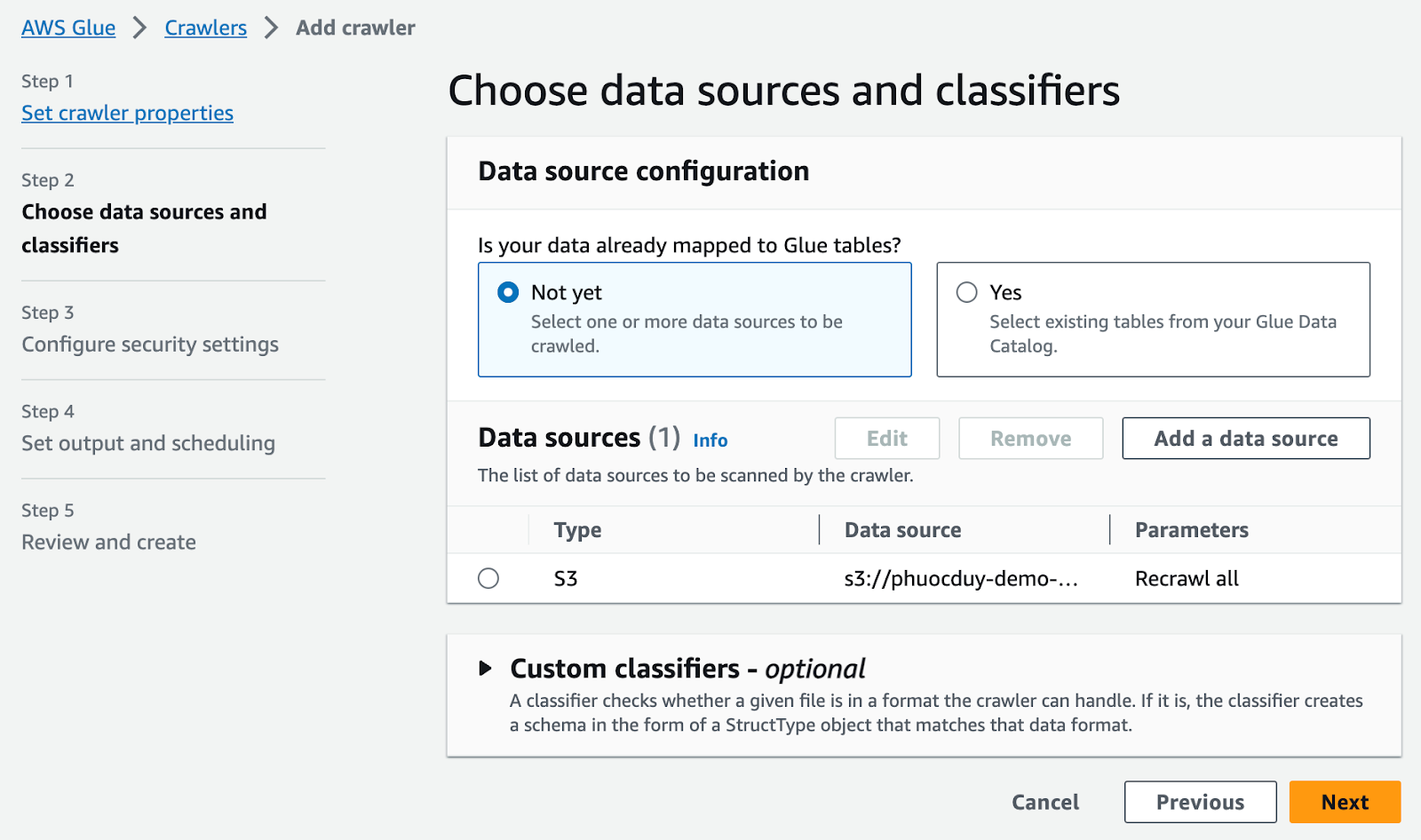
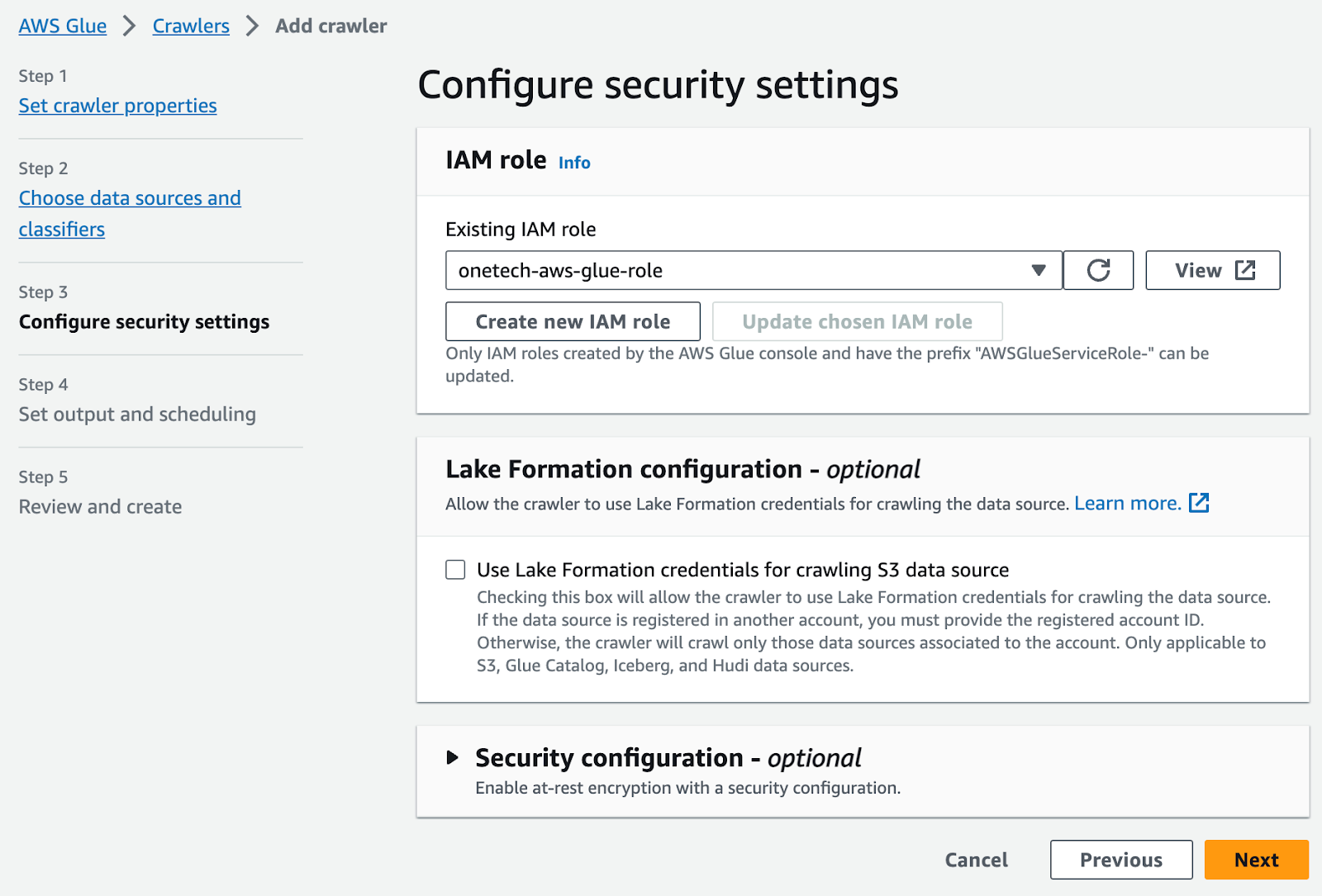
Chọn Next
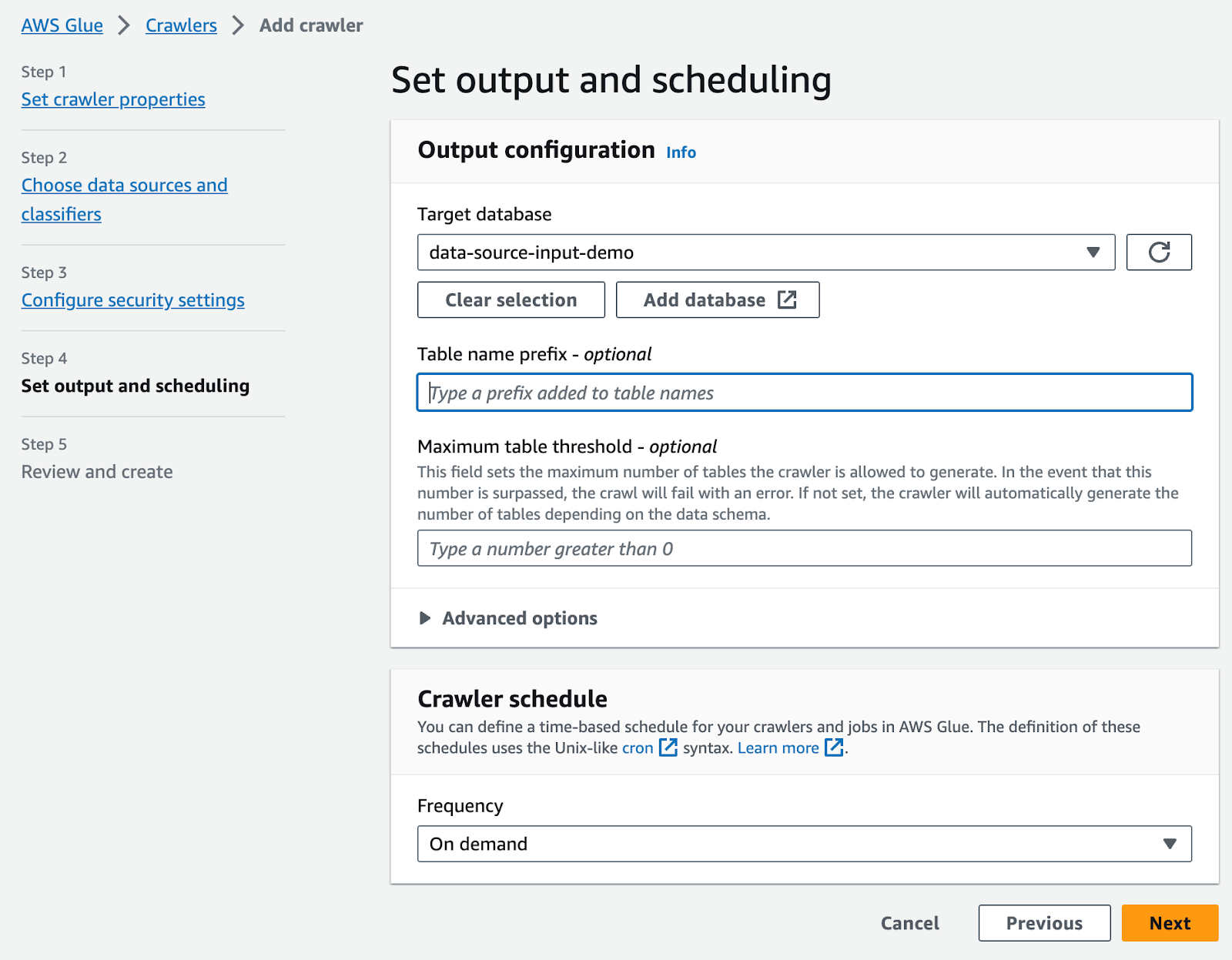
Crawler schedule chọn On Demand
Chọn Next
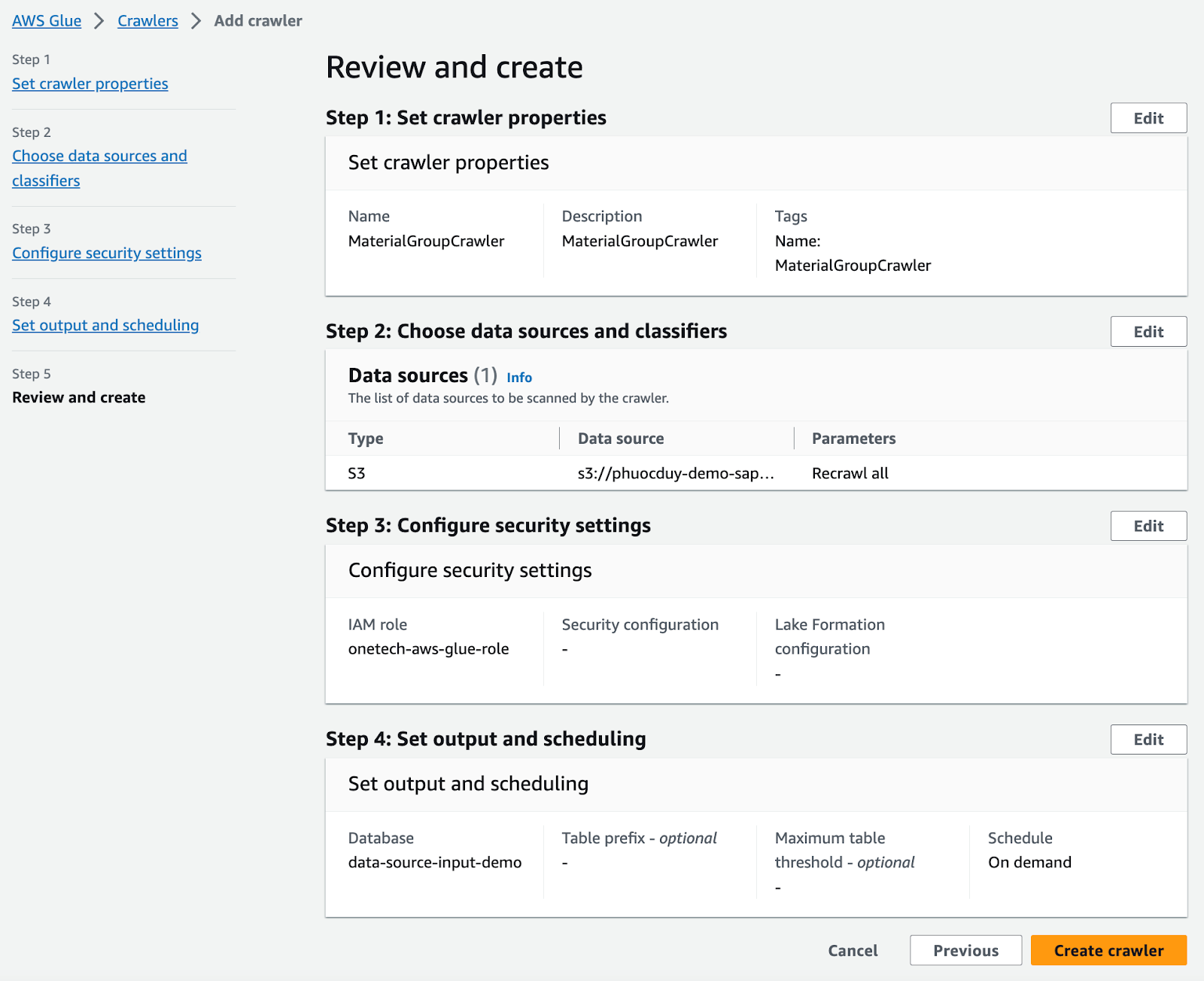
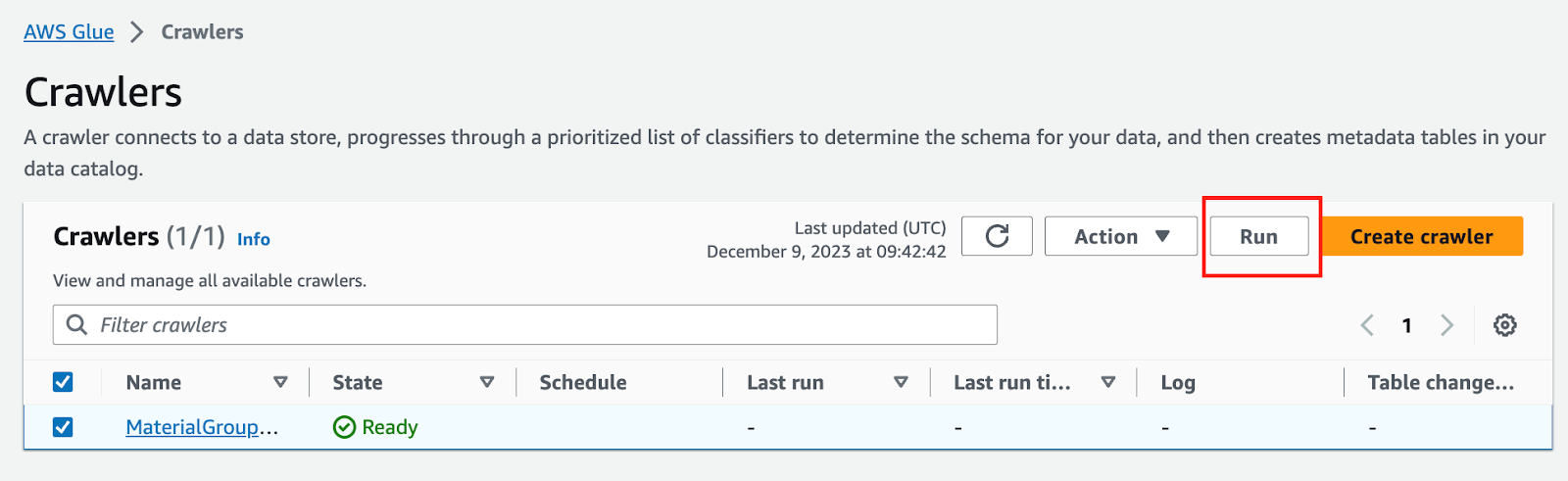
Sau khi run thành công ta sẽ có tables như sau:
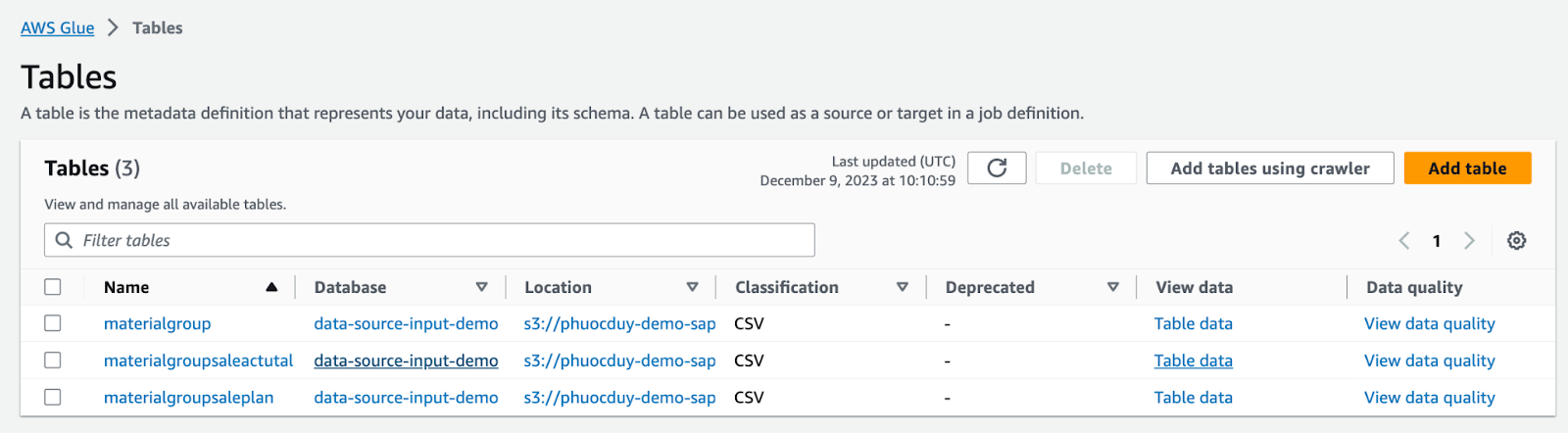
Ở đây sẽ sử dụng AWS Athena để query
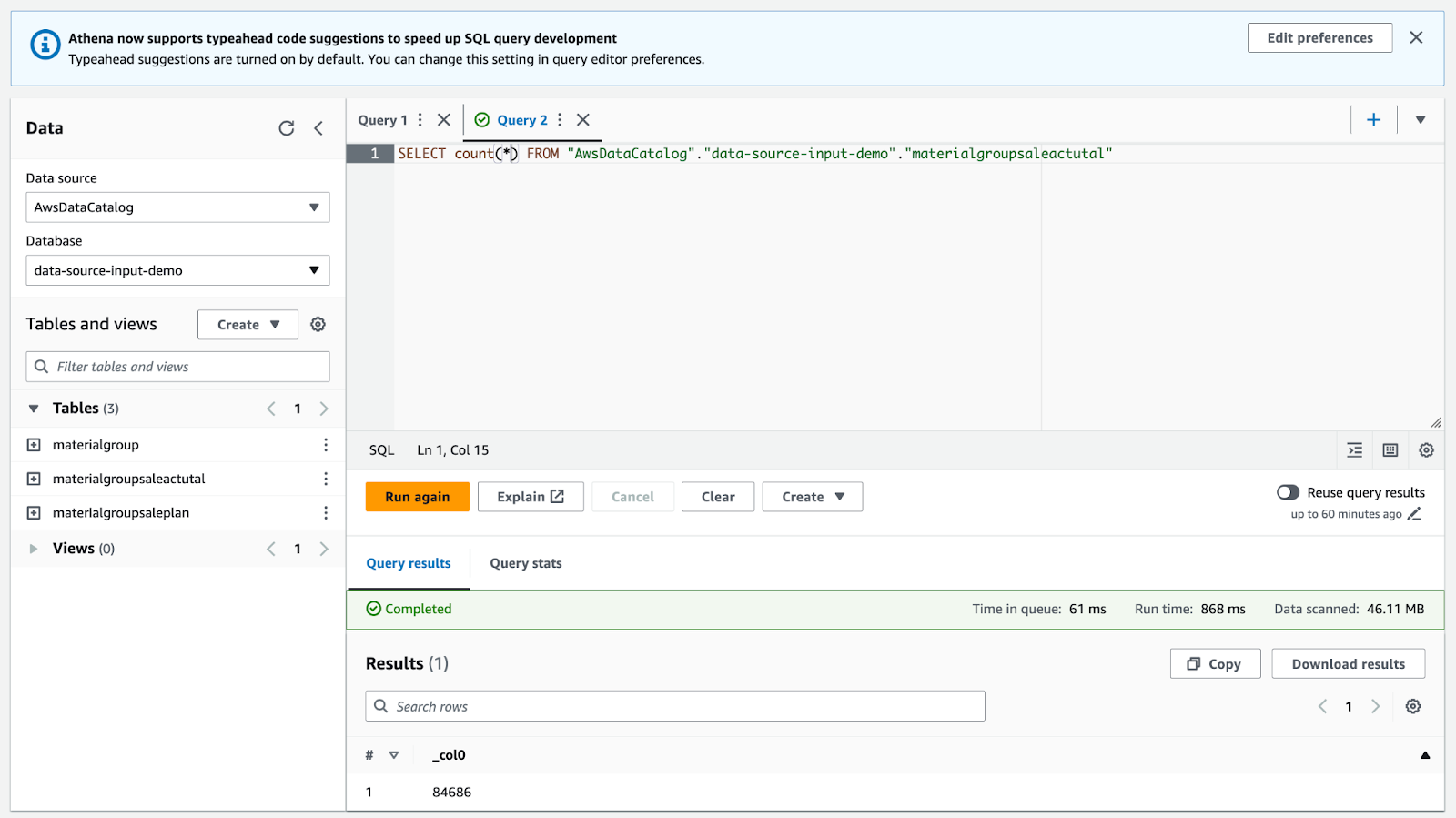
6. Create Job để transform dữ liệu từ file Data Catalog vào file Parquet
Parquet là một định dạng file lưu trữ dữ liệu phổ biến được sử dụng trong lĩnh vực phân tích dữ liệu lớn.
Đặc điểm của Parquet:
- Là định dạng cột, lưu trữ dữ liệu theo cột thay vì hàng như csv hay json. Điều này cho phép truy xuất ngẫu nhiên hiệu quả hơn.
- Sử dụng thuật toán nén lượng giải nén cao. Giảm kích thước file xuống 1/3 so với định dạng text thông thường.
- Tối ưu hóa cho việc đọc ghi song song, phù hợp xử lý dữ liệu lớn trên hệ thống phân tán.
- Tương thích tốt với hệ sinh thái Hadoop (HDFS, Hive, Spark).
- Ngôn ngữ lập trình phổ biến như Python, R, Java đều có thư viện hỗ trợ đọc ghi Parquet.
Nhờ những ưu điểm trên, Parquet ngày càng phổ biến, thay thế dần các định dạng cũ như csv, json trong lĩnh vực phân tích dữ liệu.
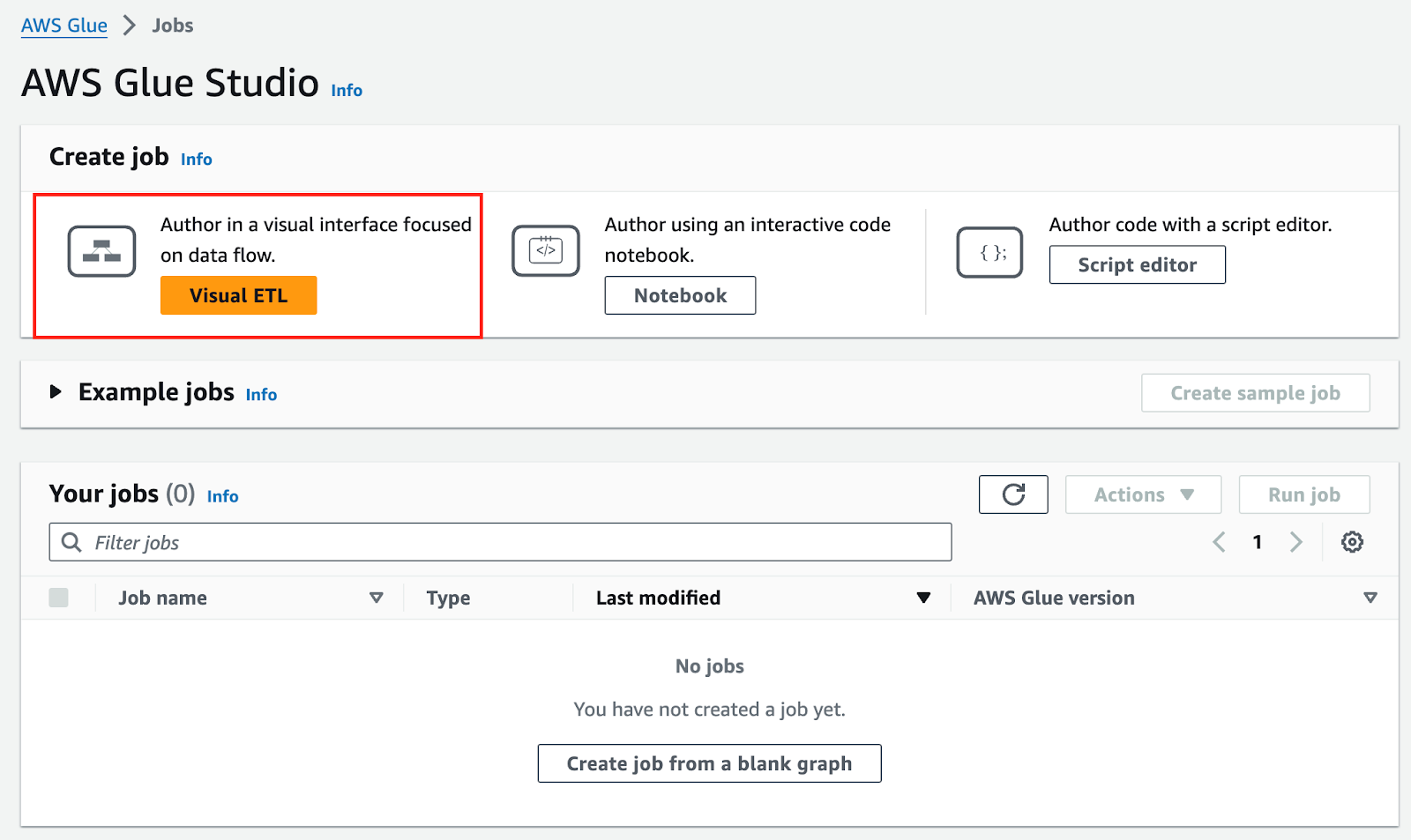
Vào màn hình aws console Glue > ETL Jobs > Visual ETL > AWS Glue Studio
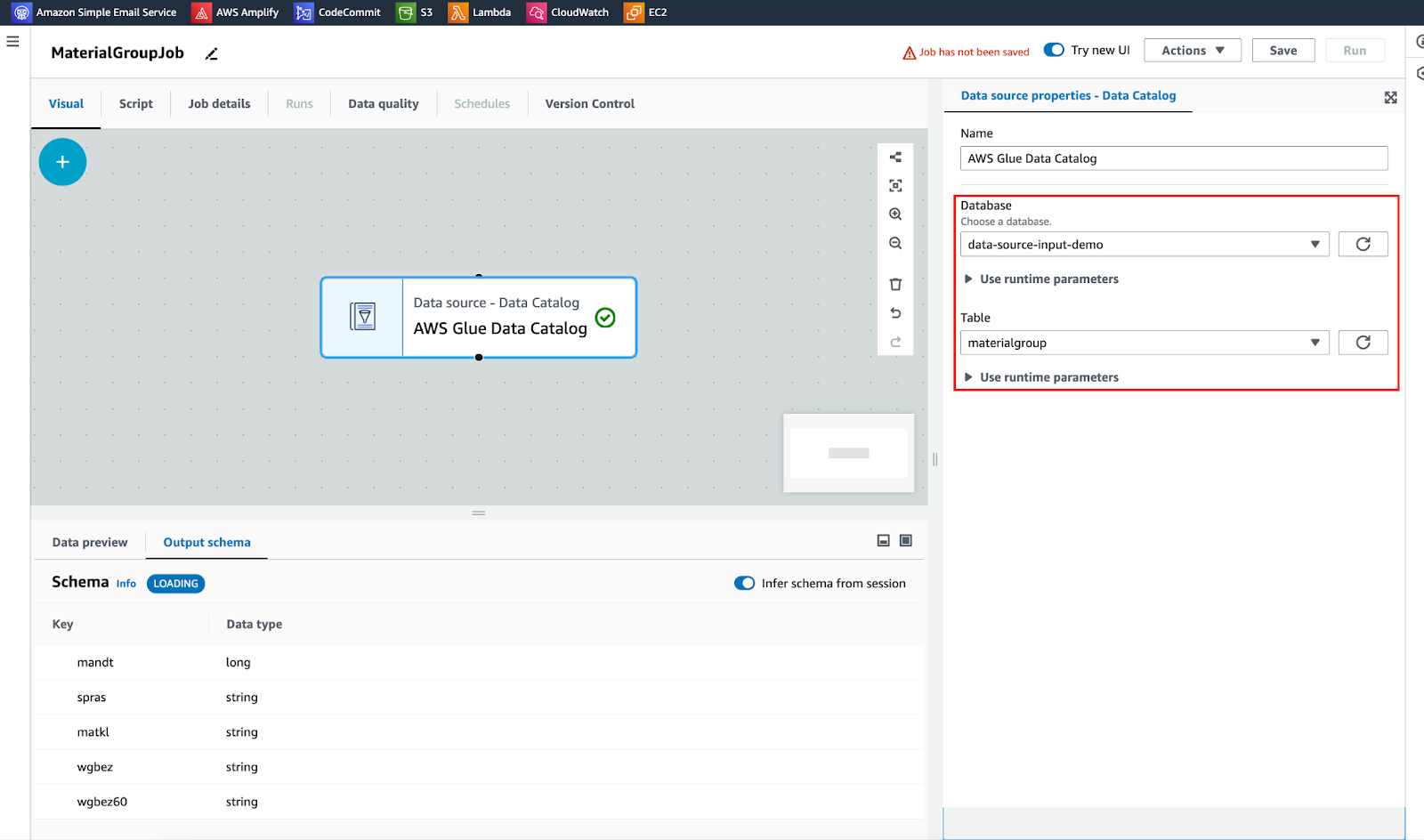
Source: Aws Glue Data Catalog
Transform: Change Schema, target item để sửa lại tên cột và không xuất ra những cột không cần thiết
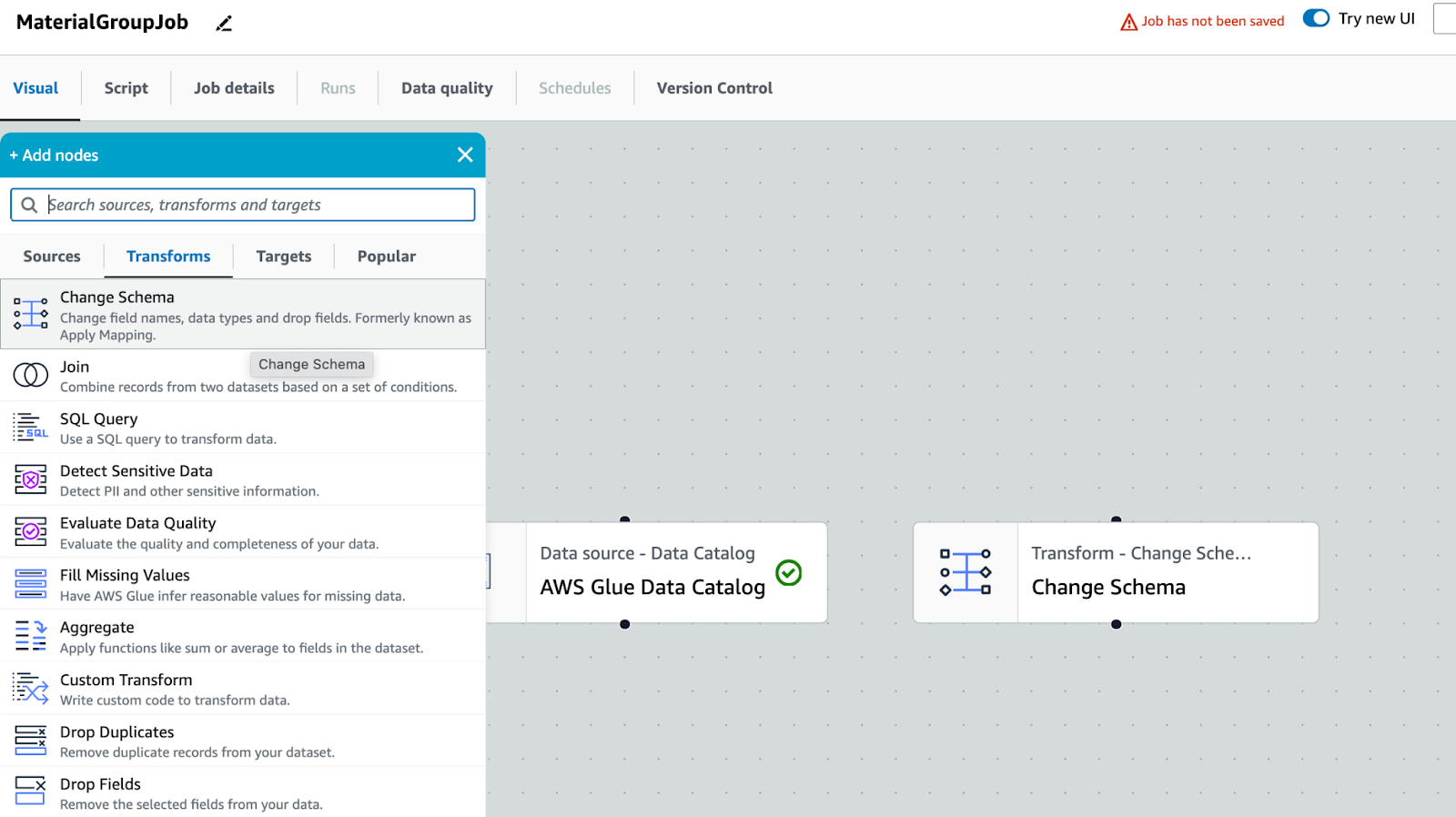
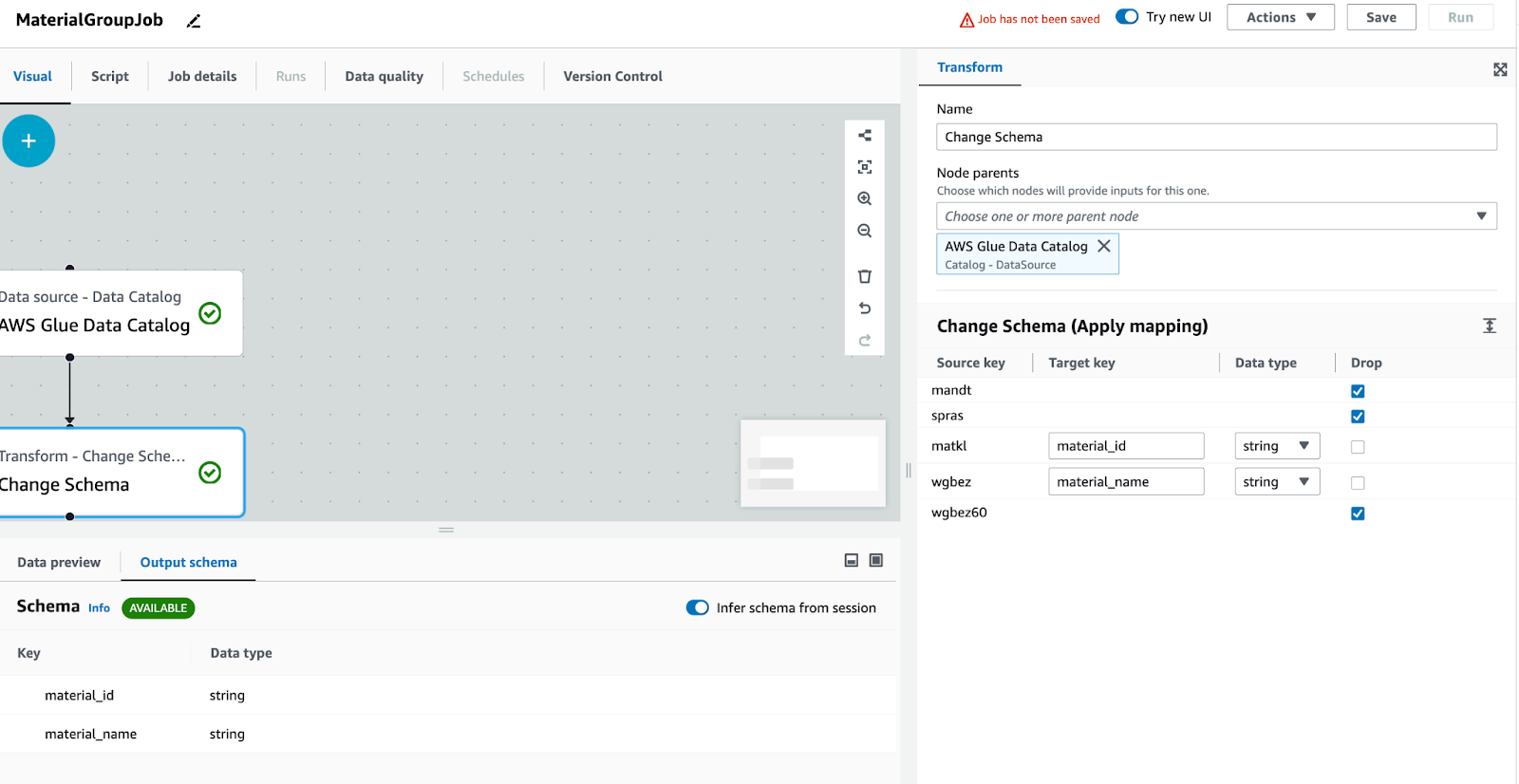
Các cột khác nếu không sử dụng thì xoá
Target: Amazon S3, sau khi job data được xử lý xong file parquet sẽ được lưu trữ vào S3/data-source-output-demo/
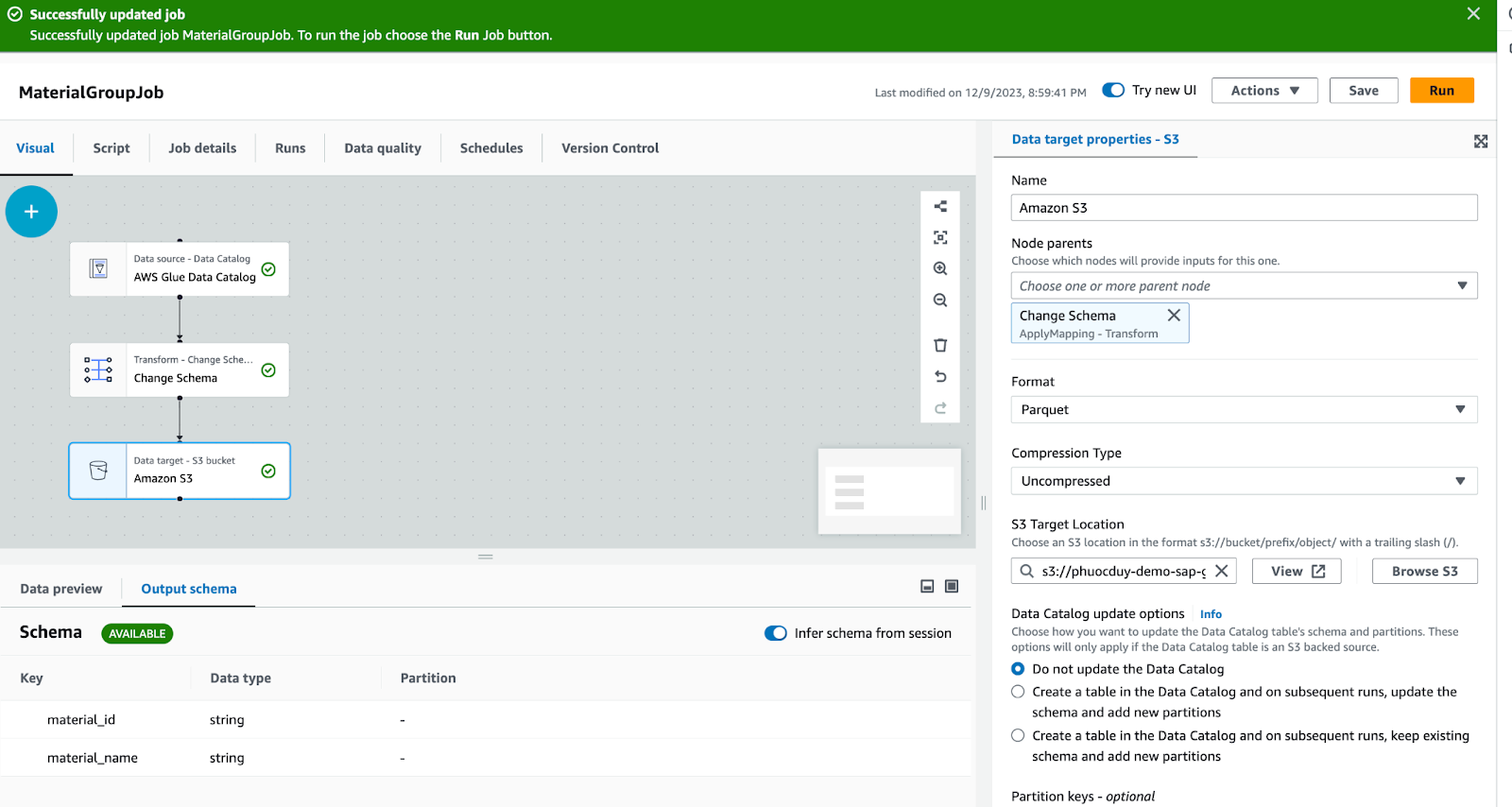
Bấm vào nút Run để job thực hiện xử lý data

Sau khi job chay xong ta vào S3/data-source-output-demo/ kiểm tra
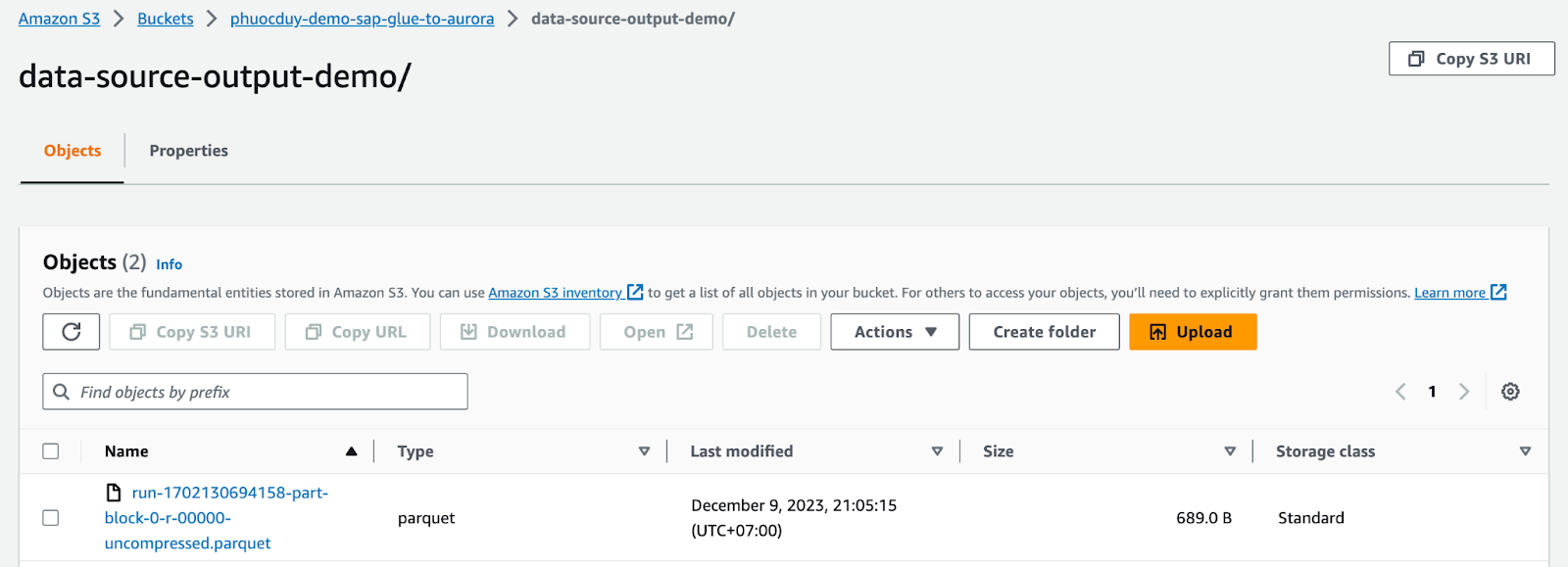
Sau khi check các file Parquet ok tiến hành đưa dữ liệu vào Aurora Mysql
7. Tận dụng lại bước 6 để đưa file dữ liệu trên vào Aurora
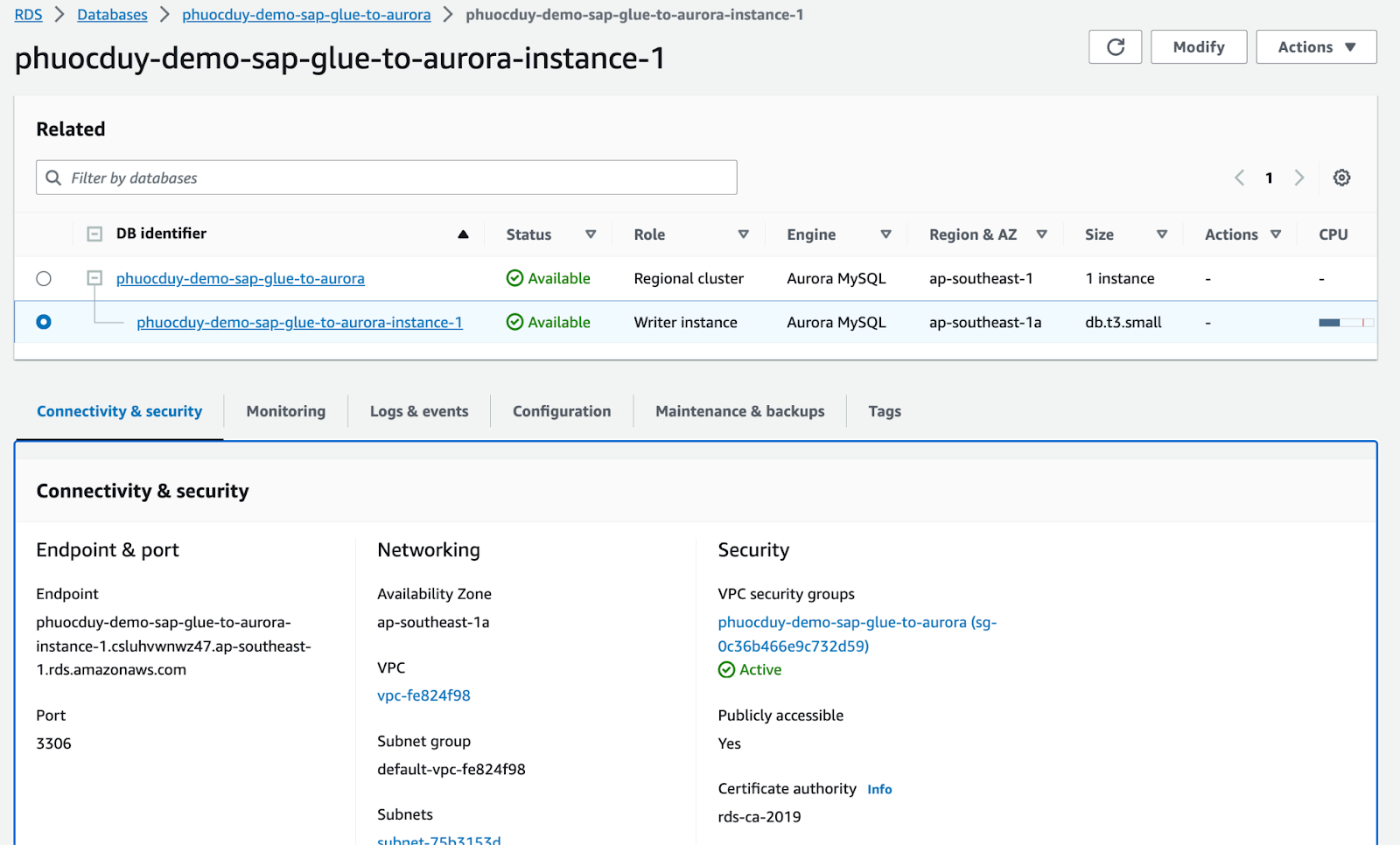
Để import vào mysql trước tiên chúng ta cần tạo 1 Aurora mysql database.
Link hướng dẫn tạo Aurora.
Ở ví dụ này Aurora sử dụng mysql 5.7, public access.
Thực hiện việc Import vào Aurora
Source: Aws Glue Data Catalog
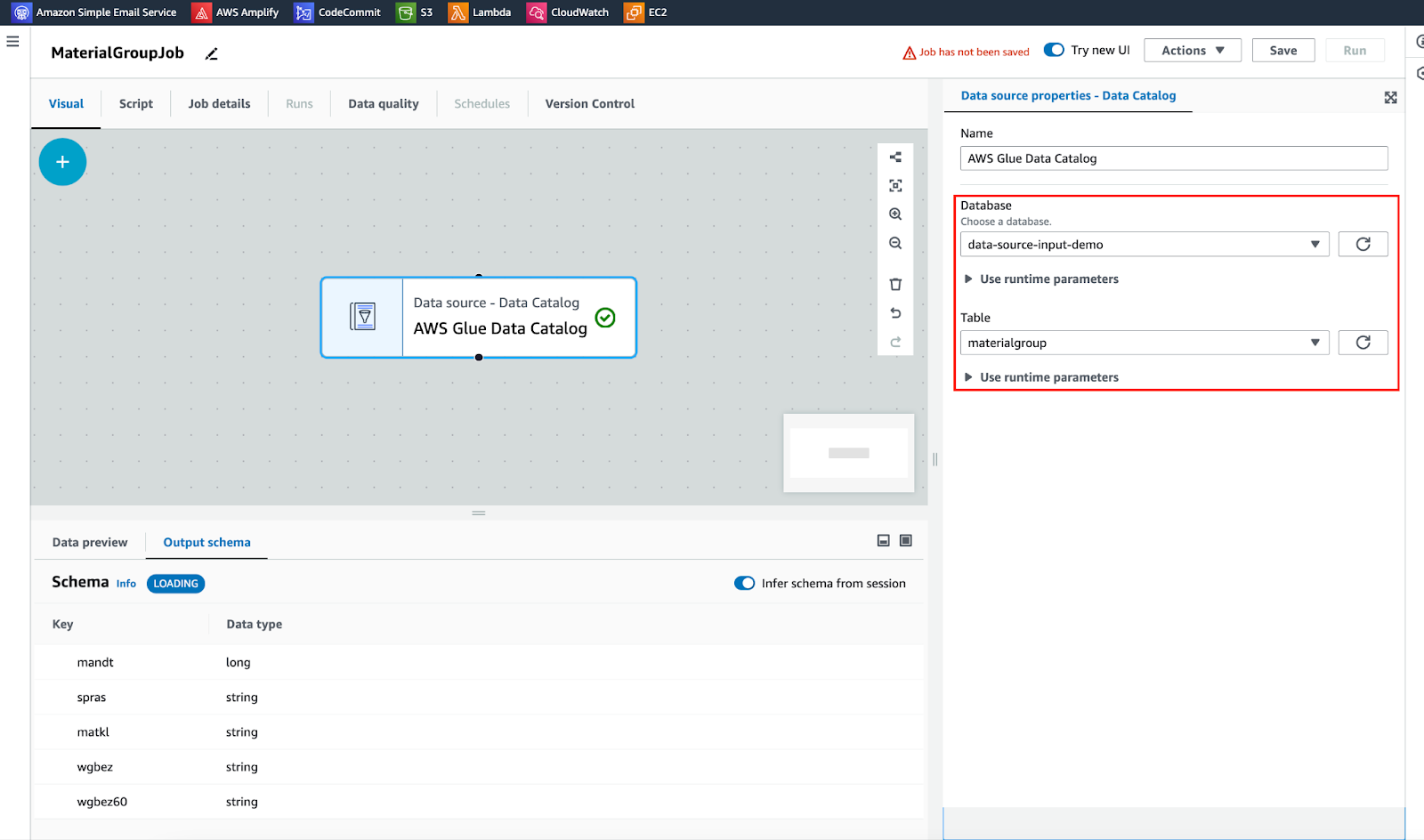
Transform: Change Schema, target item để sửa lại tên cột và không xuất ra những cột không cần thiết
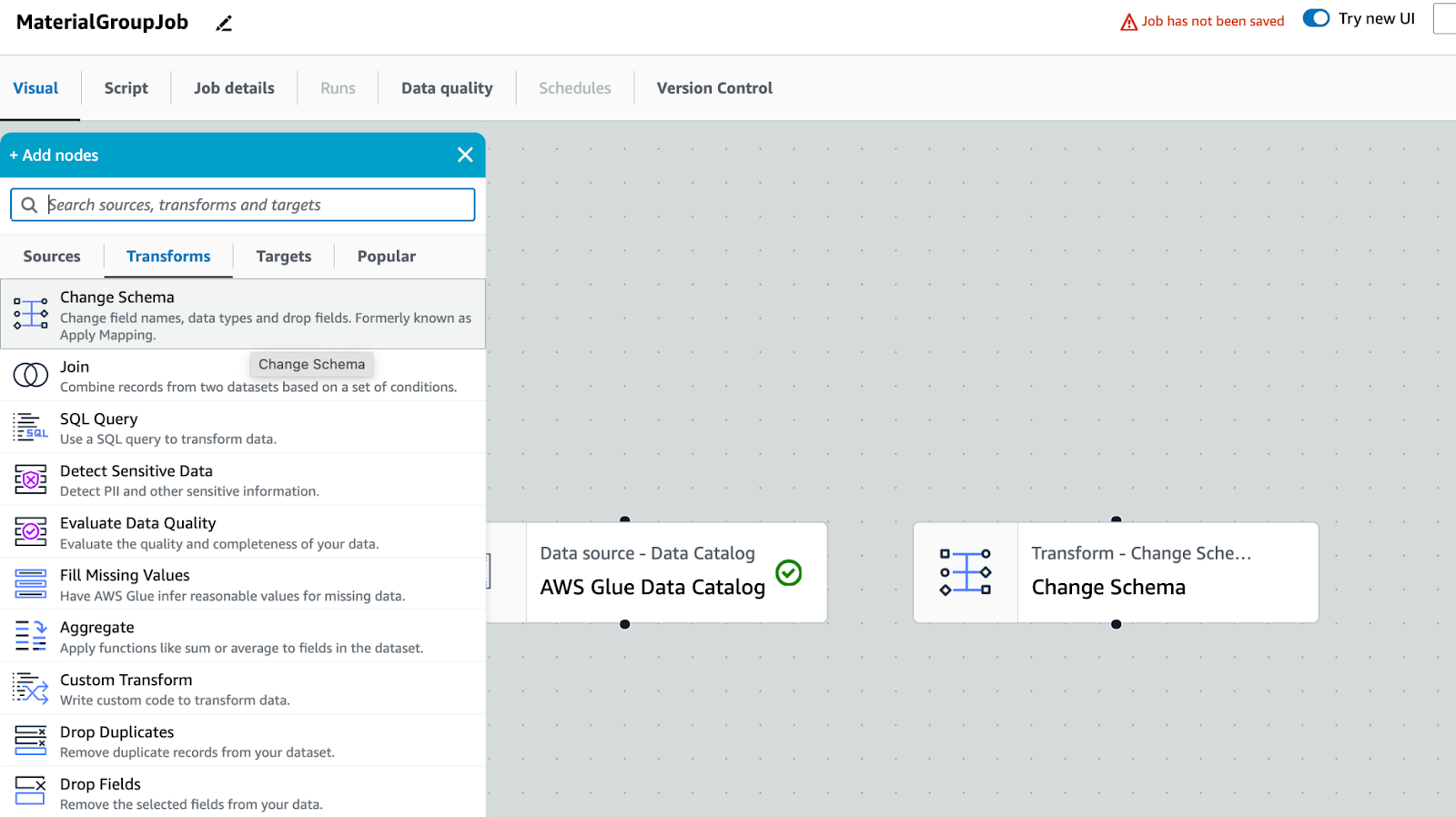

Các cột khác nếu không sử dụng thì xoá
Để tiếp tục đưa dữ liệu target vào Aurora bước này chúng ta không thể sử dụng Visual mà cần chuyển qua script để code. Bạn có thể tham khảo đoạn code bên dưới:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node1702178138796 = glueContext.create_dynamic_frame.from_catalog(
database="data-source-input-demo",
table_name="materialgroup",
transformation_ctx="AWSGlueDataCatalog_node1702178138796",
)
# Script generated for node Change Schema
ChangeSchema_node1702178150269 = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node1702178138796,
mappings=[
("matkl", "string", "material_id", "string"),
("wgbez", "string", "material_name", "string"),
],
transformation_ctx="ChangeSchema_node1702178150269",
)
AmazonS3_node1702130225660 = glueContext.write_dynamic_frame.from_options(
frame=ChangeSchema_node1702178150269,
connection_type="mysql",
connection_options={
"url": "jdbc:mysql://aurora-endpoint-url:3306/database_name",
"dbtable": "table_name",
"user": "admin",
"password": "password"
},
transformation_ctx="AmazonS3_node1702130225660",
)
job.commit()
KẾT QUẢ
Sau đó ta bấm Run theo dõi và xem kết quả:

Kiểm tra kết quả:
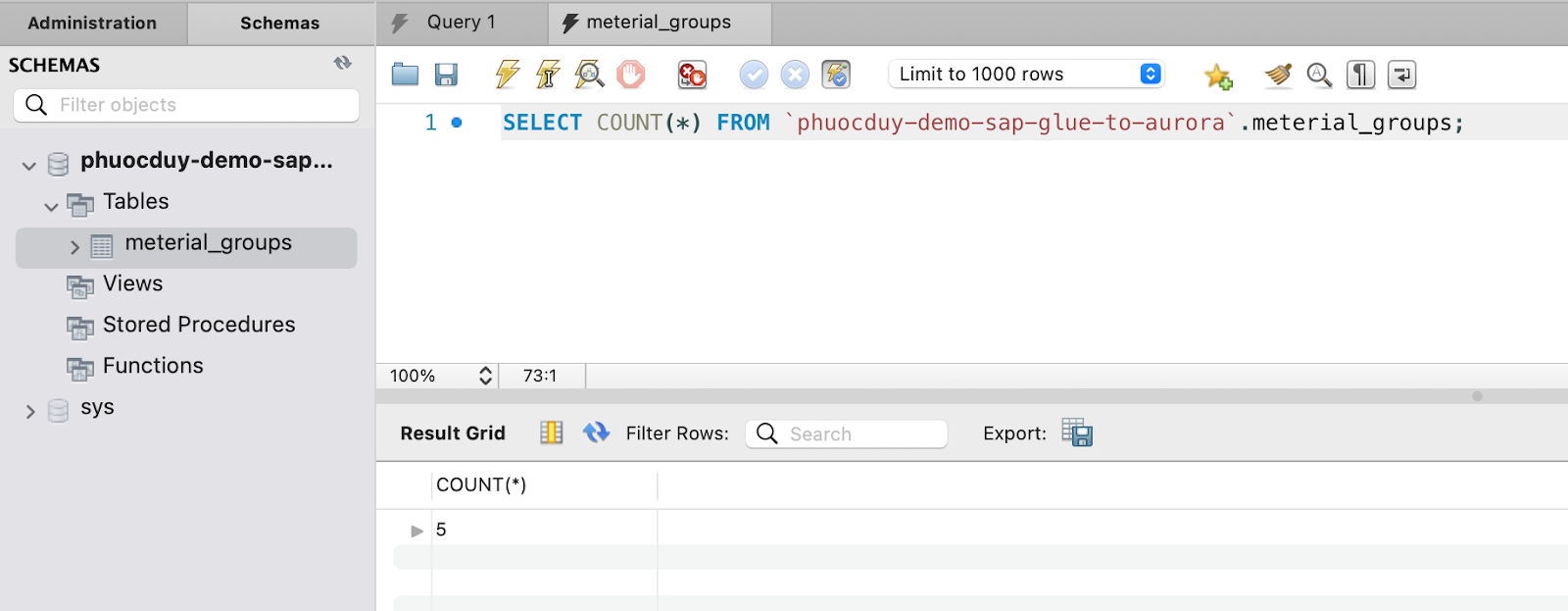
Chúc các bạn thành công!
Lưu ý nhớ xoá hết các resource liên quan để tránh trường hợp phát sinh chi phí.

OneTech Asia là công ty chuyên cung cấp các giải pháp phát triển phần mềm và dịch vụ công nghệ thông tin chất lượng cao. Chúng tôi tự hào về kinh nghiệm và chuyên môn trong việc phát triển website và các hệ thống web lớn trên AWS cho các khách hàng trong và ngoài nước. Hãy liên hệ với chúng tôi để nhận được hỗ trợ tư vấn và đánh giá website nếu bạn đang có ý định xây dựng lại nhé!






